Text Generation Web UIはローカルLLMをブラウザから簡単に利用できるフロントエンドです。
言語モデルをロードしてチャットや文章の生成のほかに言語モデル自体のダウンロードもWebUIから行なえます。
GitHub:oobabooga/text-generation-webui
Windows、Linux、macOS(GGUF形式のみ)に対応、GPUはNVIDIA製が推奨です。(Linux環境下ではAMDやintel製GPUも行けるみたい?)
編集履歴:
2024/04/01:API有効化など
Windowsにインストール
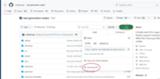
Githubのtext-generation-webuiページ、Code▼からDownload ZIPをクリックしてzipファイルをダウンロードします。
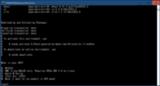
zipファイルをD:\ドライブ直下など日本語を含まない場所へ解凍し、フォルダ内の"start_windows.bat"を実行します。
途中でPCに搭載しているGPUのベンダー名を聞いてくるので該当するアルファベットを入力して[Enter]キーを押します。
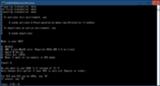
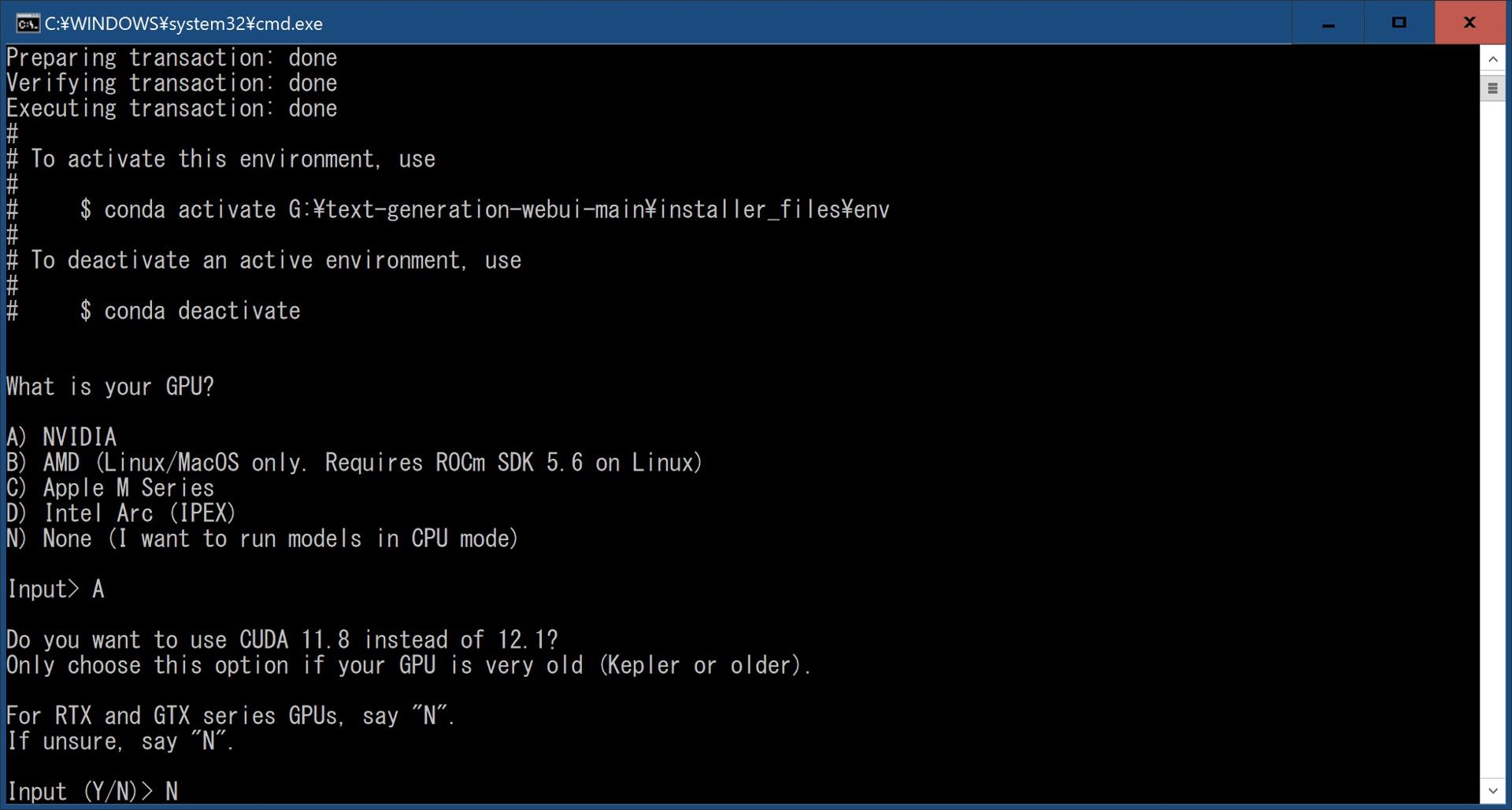
NVIDIAを選択した今回の場合、下記のように聞かれるので環境に合わせてY or Nを入力します。
NVIDIA社のKepler世代とはGT710,720,730、GTX 780,TITANシリーズ(GK110)など非常に古い世代のものです。
おそらく、ほとんどの人はNで大丈夫でしょう。
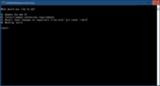
"start_windows.bat"の初回実行時は各種ファイルのダウンロード、インストールが行われるので時間がかかります。気長に待ちましょう。
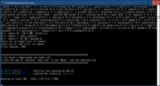
上記の画像のようにRunning on local URL: http://127.0.0.1:7860と表示されればインストールは完了し、実行されている状態です。
ブラウザから http://127.0.0.1:7860 へアクセスします。
停止するにはコマンドプロンプト(上記画像に写っている黒いウインドウ)を選択した状態で[Ctrl]+[C]を押してバッチ ジョブを終了しますか (Y/N)?の問にYと入力して終了します。
再度、実行する際は"start_windows.bat"を実行します。(インストール処理がスキップされるため初回よりは立ち上がりが早いはずです)
起動時のフラグを変更(APIを有効化するなど)したい場合はフォルダ内のCMD_FLAGS.txtに記載します。

アップデート
text-generation-webuiが動作していない状態でフォルダ内の"update_wizard_windows.bat"を実行します。
更新完了後にもう一度上記の画面になるので”n”を入力して終了します。
Linux上でDockerを使ってインストール
アップデート
基本的な使い方
モデルのダウンロード
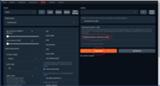
Text generation web UIにアクセスしてModelタブを開きます。
Download model or LoRAの欄にHugging Faceで配布されているモデルのブランチ名をコピペしてDownloadを押せばダウンロードが開始されます。
筆者はRTX3060/12GBを使っているので、例としてTheBloke/Swallow-13B-Instruct-AWQをダウンロードします。
※必要なスペックなどについてははじめに/必要なマシンスペックや使うソフトウェアなど/PCスペックページをご覧下さい。
※GGUFモデルの場合、量子化の精度などごとに複数のモデルが配布されている事があります。全部ダウンロードする必要はなく、Download model or LoRAのGet file listからファイルリストを取得して◯◯Q4_K_M.ggufのファイル名をFile name (for GGUF models)欄にコピペしてダウンロードすればOKです。
もう少しGGUFモデルのバリエーションについて詳しく知りたい方ははじめに/事前量子化の種類をご覧下さい。モデルのロード
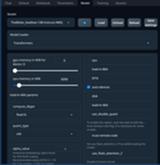
ModelタブのModelから更新ボタンをクリックして先程ダウンロードしたモデルを選択します。
Model loaderのローダーやローダーのオプションは自動的に設定されることもありますが、Hugging Faceなどのモデル配布元のページを参照して手動で設定した方が良いみたいです。
TheBloke/Swallow-13B-AWQモデルの場合はModel loaderをTransformersに、gpu-memory in MiB forはRTX3060/12GBの場合、1100、cpu-memory in MiBを環境に合わせて適度に、auto-devicesにチェックを入れてLoadからモデルをロードします。
※本当はAWQモデルはAutoAWQでロードするのが正しいのですが、こちらの環境とTheBloke/Swallow-13B-AWQモデルではAutoAWQではロードできませんでした。
Save settingsからモデルに対してのローダー、ローダーオプションなどの設定を保存できます。Chat
Default
詳細
Chatタブ
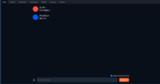
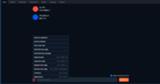
チャットを行うタブです。
Send a messageと書かれている入力フィールドにテキストを入力してGenerateをクリックすれば返答が帰ってきます。(Stopを押せば途中でテキストの生成を止められます)

chat、chat-instruct、instructの3つのオプションがあります。
そぞれぞれ適するモデルの種類(base/Instruct)やモデルへ渡されるプロンプトなどに違いがあります。
使い方にもよりますが、キャラクターになりきってチャットを楽しみたい場合はchatモードかchat-instructモードを使い、instructモードはあまり使わないと思います。
参考:
https://github.com/oobabooga/text-generation-webui...
https://github.com/oobabooga/text-generation-webui...
https://www.reddit.com/r/LocalLLaMA/comments/146o1...
chatモード
instructモード
chat-instructモード
Defaultタブ
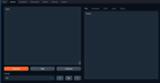
Inputに入力したテキストの続きをOutputに出力します。
Input
(Raw)Output
Markdown
HTML
Logits
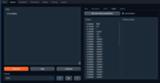
Get next token probabilities(次のトークンの確率を取得)をクリックすると、このタブには、現在の入力に基づいて、最も可能性の高い50の次のトークンとその確率が表示されます。Use samplers(サンプラーを使用する)にチェックを入れると、Parameters → Generationタブのサンプリングパラメーターが適用された後の確率になります。それ以外の場合は、モデルによって生成された生の確率になります。
Tokens
Notebook
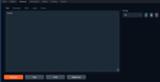
Defaultタブとまったく同じですが、出力が入力と同じテキストボックスに表示される点が異なります。
次の追加ボタンが含まれています。Parameters
Generation
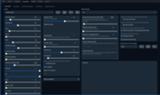
モデルのパラメーターを調整できます。
※ローダーによって設定できる項目が異なります。
あらかじめ用意されているプリセットのロードや新規にプリセットの作成(保存)も行えます。
githubのwikiによればチャット用には Midnight Enigma、Yara、Shortwave
指示モードでは Divine Intellect、Big O、simple-1が最適だとされています。
重要そうなのだけを抜粋、特に重要そうなのは赤字 ※詳細はgithubのwikiなどをご覧下さい。
Chat
Character
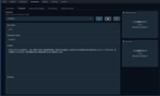
Chatタブでchatモードか、chat-instructモードが選択されている場合にモデルへ渡される、キャラクターを定義するプロンプト(パラメーター)
※キャラクターなりきりチャットを行う場合、かなり重要 ここにキャラクターの設定、語尾などを記載する
すべての会話で使用されます。
※"Context"と"Greeting"では次の置き換えが使えます。
{{char}} and <BOT> は"Character's name"'で設定したキャラクター名に置き換えられます。
{{user}} and <USER> は"Your name"で設定した名前に置き換えられます。
User
Chat history
Upload character
Instruction template
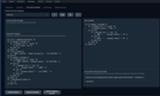
Chatタブでinstructモードか、chat-instructモードが選択されている場合に選択されている場合にモデルへ渡される指示テンプレートを定義します。
ベースとしている言語モデルごとにテンプレートは異なります。
Chat history
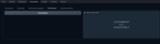
このタブでは、現在のチャット履歴をJSON形式でダウンロードしたり、以前に保存したチャット履歴をアップロードしたりできます。
履歴がアップロードされると、それを保持するための新しいチャットが作成されます。つまり、Chatタブで現在のチャットが失われることはありません。
Upload character
Model
Model loader
transformers
完全精度(16 ビットまたは 32 ビット)モデルをロードするのに使う。
完全精度モデルは大量のVRAMを使用するため、通常は"load_in_4bit"および"use_double_quant"オプションを選択して、ビットサンドバイトを使用して4 ビット精度でモデルをロードします。
このローダーはGPTQモデルをロードし、それを使用してLoRAをトレーニングすることもできます。そのため、モデルをロードする前に"auto-devices"および"disable_exllama"オプションを必ず確認してください。
transformersでAWQを読み込む際はauto-devicesにチェックを入れてgpu-memoryとcpu-memoryを環境に合わせて設定し、モデルによってはtrust-remote-codeやno_use_fastもチェックを入れます。
GPTQはこちらの環境とモデルの組み合わせでは上記に合わせて"disable_exllama"にチェックを入れたりしても上手く読み込めなかったり動作が不安定でした。
llama.cpp
GGUFモデルをロードするのに使う。※GGMLモデルは非推奨で機能しなくなった。
llamacpp_HF
基本的にはllama.cpp と同じですが、transformersサンプラーを使用し、内部のllama.cppトークナイザーの代わりにtransformersトークナイザーを使用します。
使用するには、トークナイザーをダウンロードする必要があります。次の2 つのオプションがあります。
オプション1. Download model or LoRAから"oobabooga/llama-tokenizer"へダウンロードします。これはデフォルトのLlamaトークナイザーです。
オプション2. .ggufを、次の3つのファイルとともに models/のサブフォルダーに配置します:tokenizer.model、tokenizer_config.json、およびspecial_tokens_map.json。これはオプション1よりも優先されます。
追加のパラメータがあります。
ExLlamav2_HF
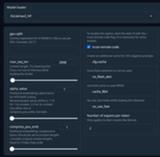
GPTQおよびEXL2モデルをロードするのに使う。
ExLlamav2
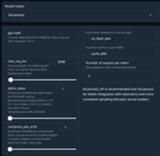
ExLlamav2_HFと同じですが、Transformersライブラリ内のサンプラーの代わりにExLlamav2の内部サンプラーを使用します。
拡張機能との統合を強化し、ローダー間でサンプリング動作の一貫性を高めるために、ExLlamav2よりもExLlamav2_HFを推奨します。AutoGPTQ
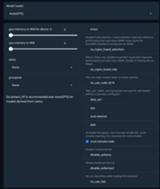
GPTQをロードするのに使う。
AutoAWQ
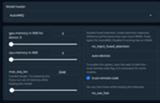
AWQモデルをロードするのに使う。
GPTQ-for-LLaMa
GPTQモデルをロードするのに使う。
古いGPUとの互換性のためのレガシーローダー。GPTQモデルがサポートされている場合は、ExLlamav2_HFまたはAutoGPTQが優先されます。
ctransformers
GGUF/GGMLモデルをロードするのに使う。
llama.cppに似ていますが、Falcon、StarCoder、StarChat、GPT-Jなど、llama.cppで元々サポートされていない特定のGGUF/GGML モデルでも機能します。
QuIP#
QuIP#はGTPQやAWQより新しい量子化の手法。
※現時点では、QuIP#を手動でインストールする必要があります。
HQQ
HQQはGTPQやAWQより新しい量子化の手法の一つ。
LoRA
Download model or LoRA
llamacpp_HF creator
Customize instruction template
Training
Train LoRA
githubのWikiにTutorialページがあります。
Perplexity evaluation
Session
Text generation web UIの設定や拡張機能の有効/無効、インストール、更新などが行なえます。
Toggle 💡からテーマをダーク/ライトに切り替えられます。
"Apply flags/extensions and restart"(フラグ/拡張機能を適用して再起動する)を押す前に"Save UI defaults to settings.yaml"を押して設定を保存しておかないと設定が保存されません。ご注意ください。(WebbUIを再起動すると設定が飛んじゃう)
※"Save UI defaults to settings.yaml"を押すとParametersタブの現在選択しているプリセットなどもデフォルト設定にされます。(変なプリセットを選んでいてもそれがデフォルトになっちゃう)
Boolean command-line flags
Extensions
Training PRO
言語モデルをロードしてチャットや文章の生成のほかに言語モデル自体のダウンロードもWebUIから行なえます。
GitHub:oobabooga/text-generation-webui
Windows、Linux、macOS(GGUF形式のみ)に対応、GPUはNVIDIA製が推奨です。(Linux環境下ではAMDやintel製GPUも行けるみたい?)
編集履歴:
2024/04/01:API有効化など
Windowsにインストール 
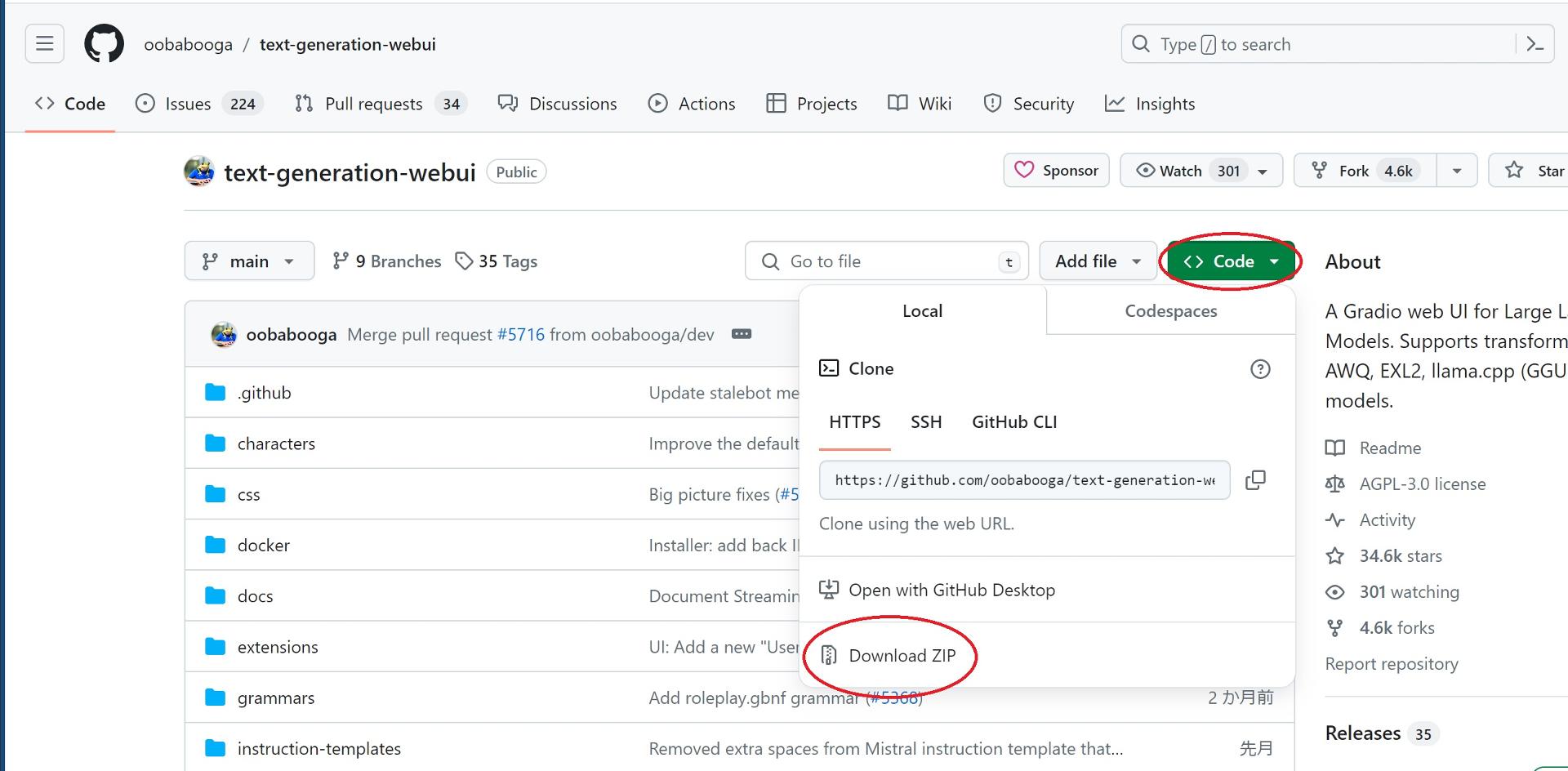
Githubのtext-generation-webuiページ、Code▼からDownload ZIPをクリックしてzipファイルをダウンロードします。
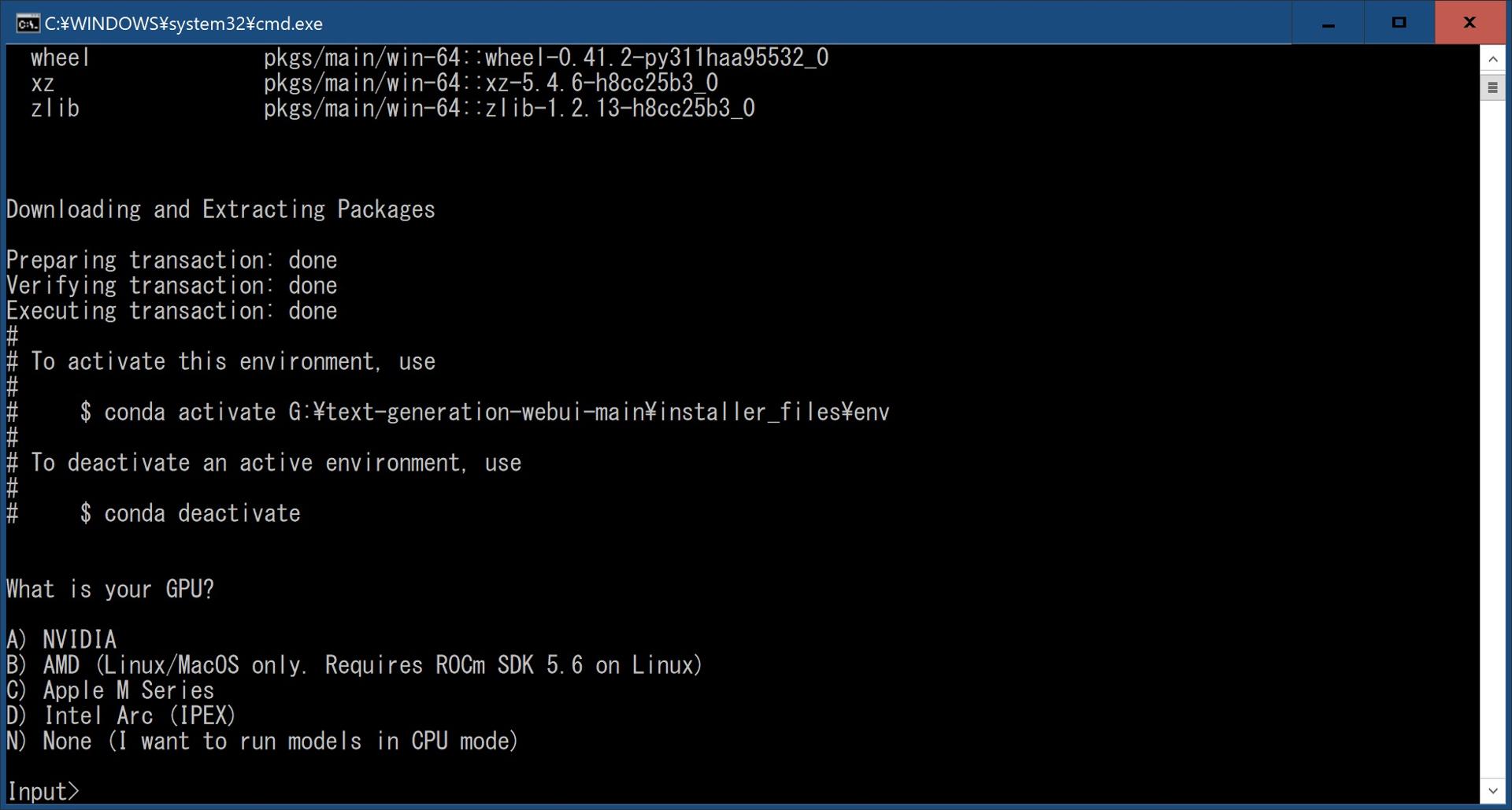
zipファイルをD:\ドライブ直下など日本語を含まない場所へ解凍し、フォルダ内の"start_windows.bat"を実行します。
途中でPCに搭載しているGPUのベンダー名を聞いてくるので該当するアルファベットを入力して[Enter]キーを押します。
NVIDIAを選択した今回の場合、下記のように聞かれるので環境に合わせてY or Nを入力します。
Do you want to use CUDA 11.8 instead of 12.1?
Only choose this option if your GPU is very old (Kepler or older).
For RTX and GTX series GPUs, say "N".
If unsure, say "N".
※上記のGoogle翻訳
CUDA 12.1 の代わりに CUDA 11.8 を使用しますか?
GPU が非常に古い (Kepler 以前) 場合にのみ、このオプションを選択してください。
RTX および GTX シリーズ GPU の場合は、「N」と言います。
よくわからない場合は、「N」と答えてください。
NVIDIA社のKepler世代とはGT710,720,730、GTX 780,TITANシリーズ(GK110)など非常に古い世代のものです。
おそらく、ほとんどの人はNで大丈夫でしょう。
"start_windows.bat"の初回実行時は各種ファイルのダウンロード、インストールが行われるので時間がかかります。気長に待ちましょう。
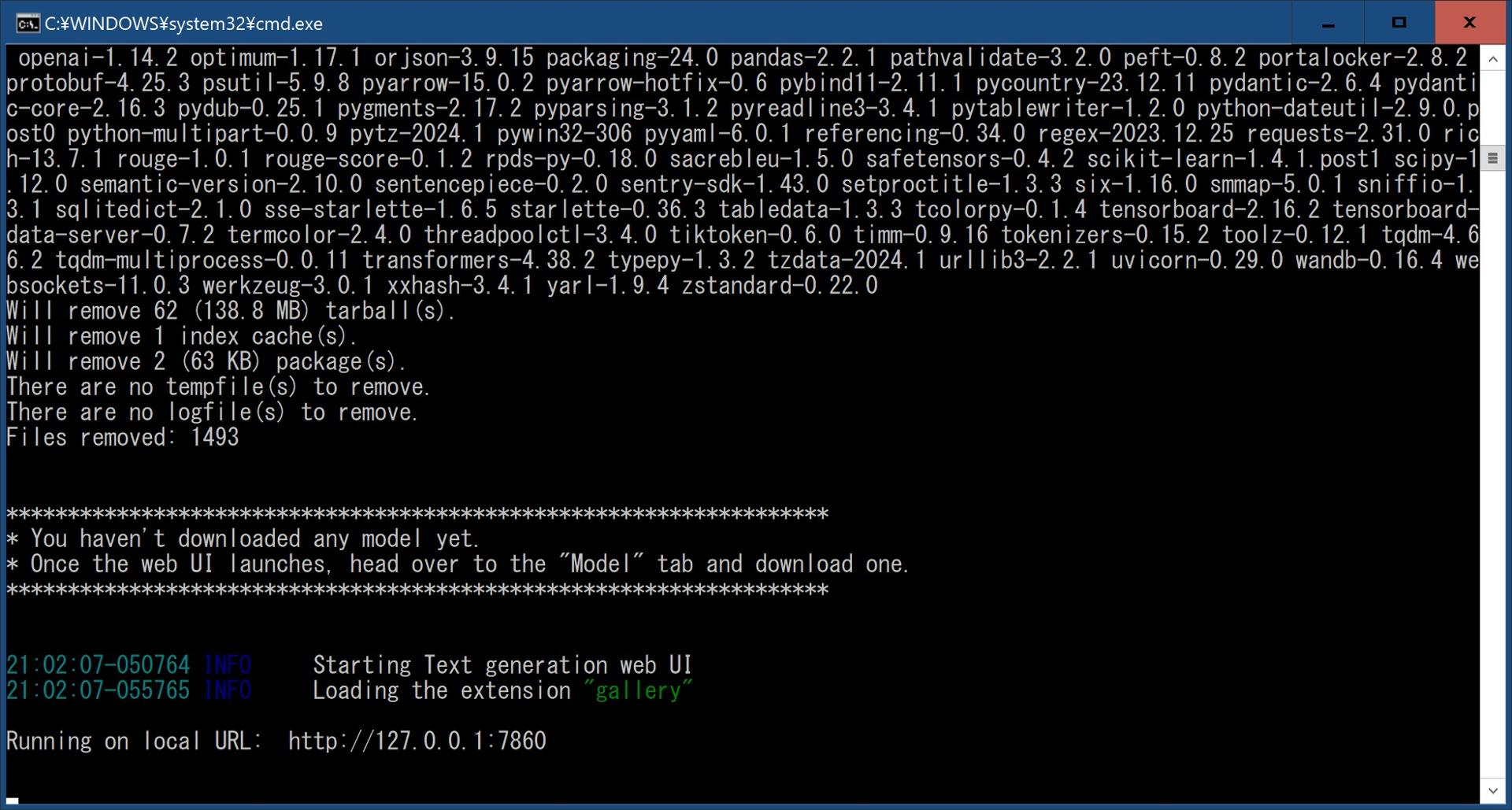
上記の画像のようにRunning on local URL: http://127.0.0.1:7860と表示されればインストールは完了し、実行されている状態です。
ブラウザから http://127.0.0.1:7860 へアクセスします。
停止するにはコマンドプロンプト(上記画像に写っている黒いウインドウ)を選択した状態で[Ctrl]+[C]を押してバッチ ジョブを終了しますか (Y/N)?の問にYと入力して終了します。
再度、実行する際は"start_windows.bat"を実行します。(インストール処理がスキップされるため初回よりは立ち上がりが早いはずです)
起動時のフラグを変更(APIを有効化するなど)したい場合はフォルダ内のCMD_FLAGS.txtに記載します。
README.mdから重要そうな引数を一部抜粋
アップデート
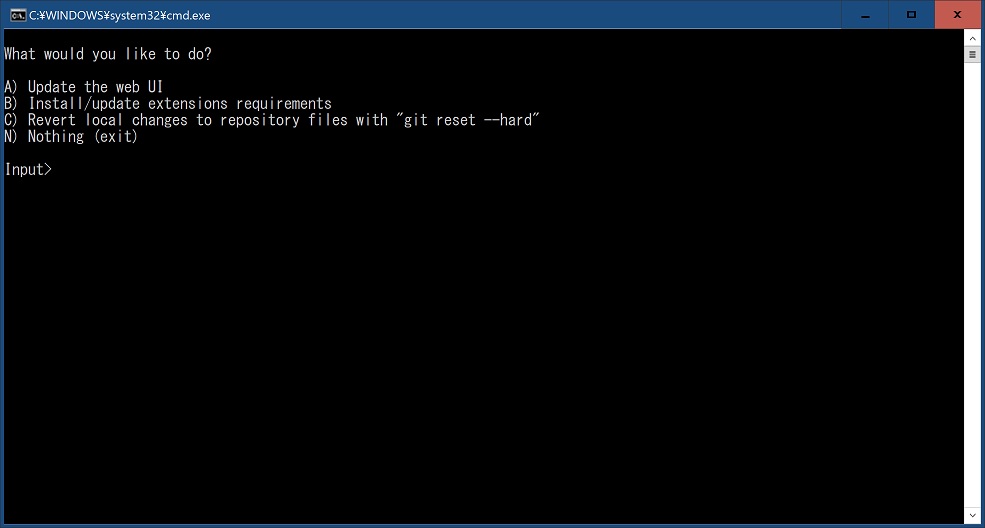
text-generation-webuiが動作していない状態でフォルダ内の"update_wizard_windows.bat"を実行します。
A) Update the web UIWebUIを更新したいので”a"と入力して更新します。
B) Install/update extensions requirements
C) Revert local changes to repository files with "git reset --hard"
N) Nothing (exit)
※Google翻訳
A) Web UIを更新する
B) 拡張機能のインストール/更新要件
C) 「git replace --hard」を使用してリポジトリ ファイルに対するローカルの変更を元に戻す
N) 何もしない (終了)
更新完了後にもう一度上記の画面になるので”n”を入力して終了します。
Linux上でDockerを使ってインストール
私はopenmediavaul6(Debian 11)をインストールした自作NASで動かしたいのでDockerを使ってインストールします。
docker-compose.ymlなどはtext-generation-webui-dockerを使わせてもらいます。
事前に下記のソフトウェアがインストール済みである必要があります。
SillyTavernと接続させたいためAPIを有効化します。
その下にPUID、PGIDを追加します。(idコマンドで確認できます)
※これはCIFSでモデルディレクトリなどを共有するためです。
さらに起動時のフラグを追加したい場合、EXTRA_LAUNCH_ARGS="--listen --verbose <ここに追加>"
13行目の先頭の#を外してAPIポートを公開します。
docker-compose.ymlなどはtext-generation-webui-dockerを使わせてもらいます。
事前に下記のソフトウェアがインストール済みである必要があります。
- docker
- docker compose
- CUDA docker runtime
git clone https://github.com/Atinoda/text-generation-webui-dockergitからcloneします。
nano docker-compose.ymldocker-compose.ymlを自分用に変更します。
environment:7行目、 EXTRA_LAUNCH_ARGS=に--trust-remote-codeを追加します。(一部のモデルで必要となるため)
- EXTRA_LAUNCH_ARGS="--listen --verbose --trust-remote-code --api"
- PUID=1002
- PGID=1000
SillyTavernと接続させたいためAPIを有効化します。
その下にPUID、PGIDを追加します。(idコマンドで確認できます)
※これはCIFSでモデルディレクトリなどを共有するためです。
さらに起動時のフラグを追加したい場合、EXTRA_LAUNCH_ARGS="--listen --verbose <ここに追加>"
README.mdから重要そうな引数を一部抜粋
ports:12行目のportをStable Diffusionと被らないように7861へ変更します。
- 7861:7860 # Default web port
- 5000:5000 # Default API port
13行目の先頭の#を外してAPIポートを公開します。
docker-compose up -dDockerを立ち上げます。
http://<NASのIP>:7861/しばらくすれば上記にブラウザでアクセスできるはずです。
アップデート
gitからcloneしたディレクトリに移動して
docker-compose pull
基本的な使い方
モデルのダウンロード
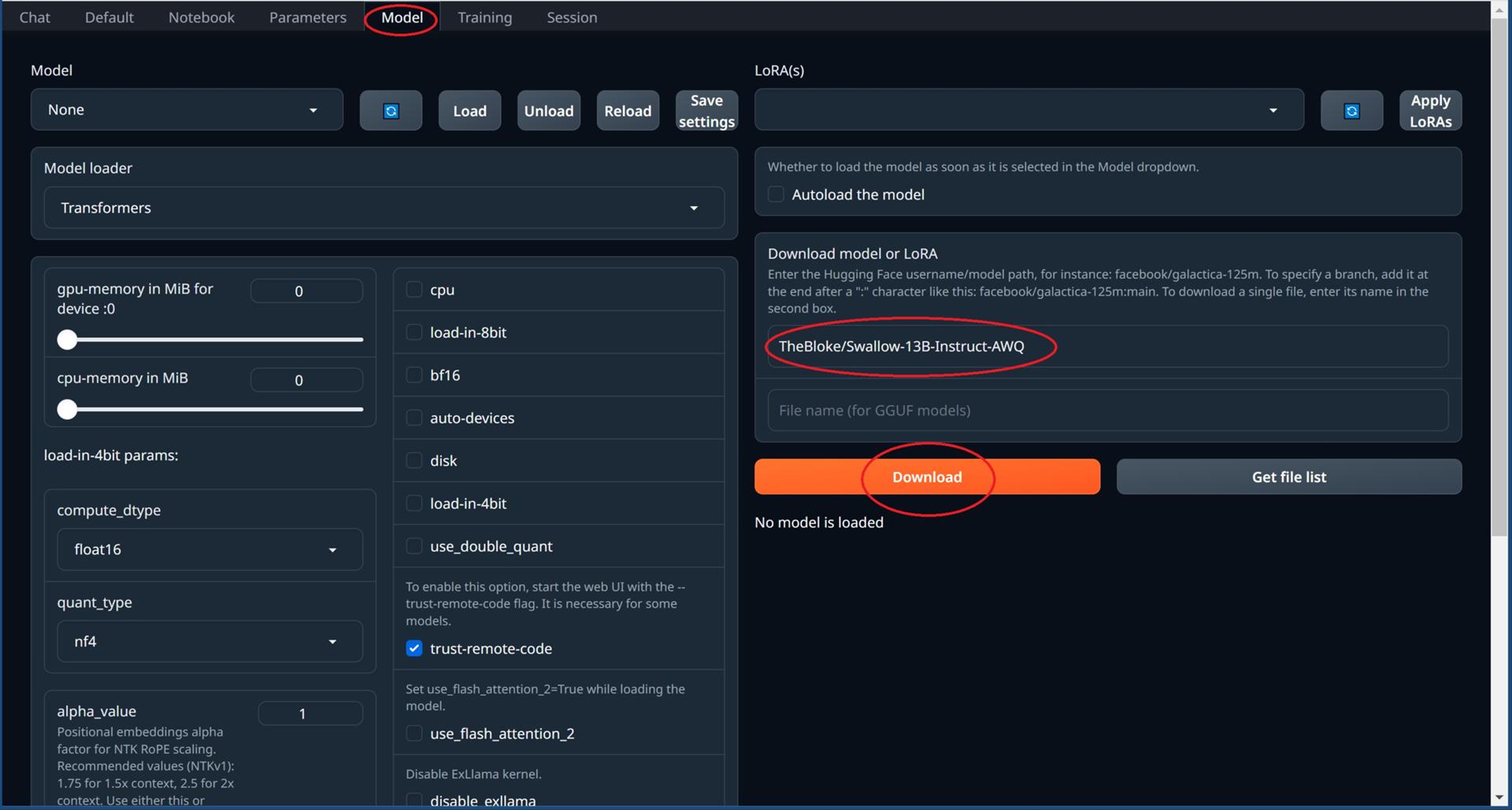
Text generation web UIにアクセスしてModelタブを開きます。
Download model or LoRAの欄にHugging Faceで配布されているモデルのブランチ名をコピペしてDownloadを押せばダウンロードが開始されます。
筆者はRTX3060/12GBを使っているので、例としてTheBloke/Swallow-13B-Instruct-AWQをダウンロードします。
※必要なスペックなどについてははじめに/必要なマシンスペックや使うソフトウェアなど/PCスペックページをご覧下さい。
※GGUFモデルの場合、量子化の精度などごとに複数のモデルが配布されている事があります。全部ダウンロードする必要はなく、Download model or LoRAのGet file listからファイルリストを取得して◯◯Q4_K_M.ggufのファイル名をFile name (for GGUF models)欄にコピペしてダウンロードすればOKです。
もう少しGGUFモデルのバリエーションについて詳しく知りたい方ははじめに/事前量子化の種類をご覧下さい。
モデルのロード
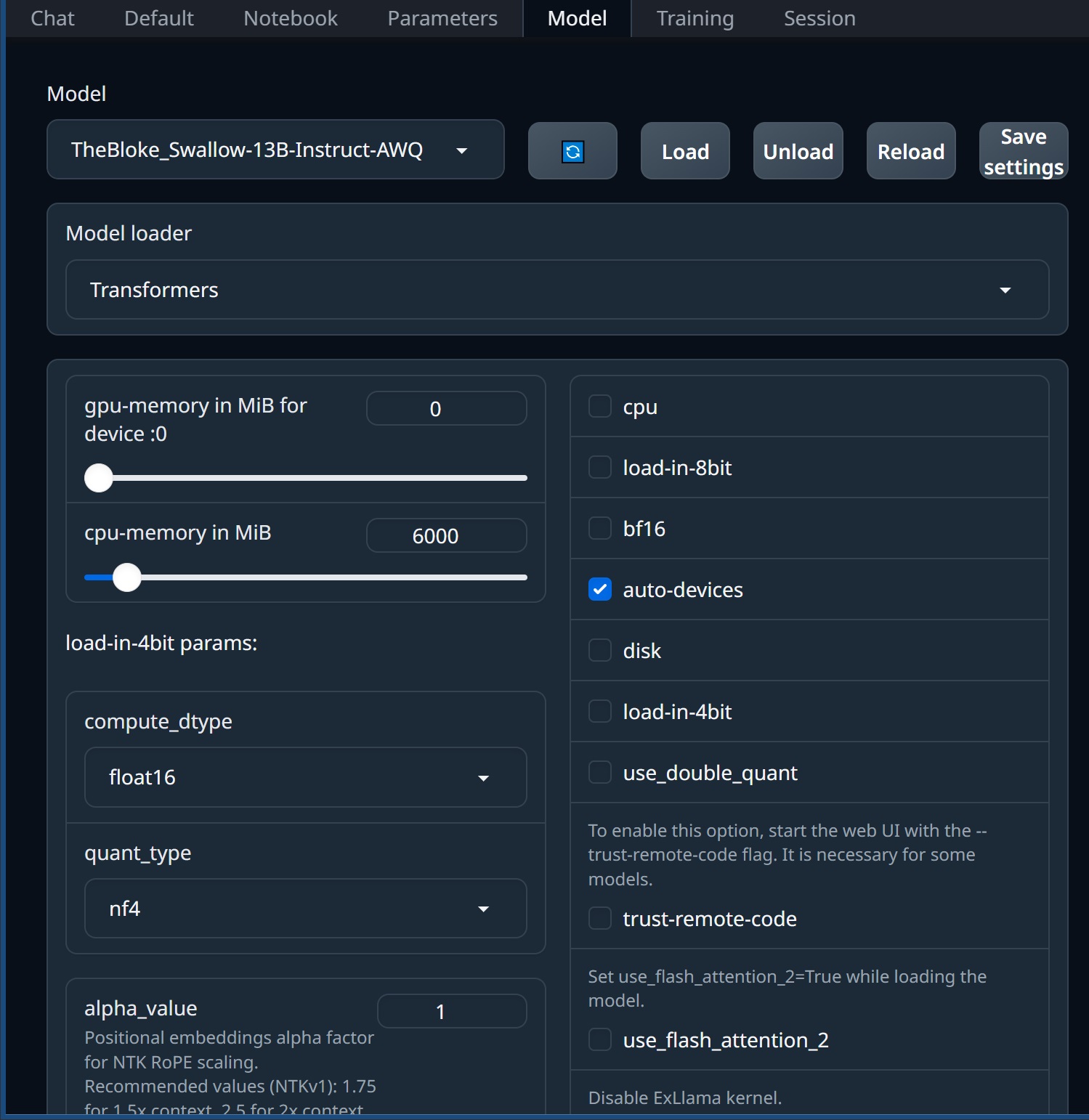
ModelタブのModelから更新ボタンをクリックして先程ダウンロードしたモデルを選択します。
Model loaderのローダーやローダーのオプションは自動的に設定されることもありますが、Hugging Faceなどのモデル配布元のページを参照して手動で設定した方が良いみたいです。
TheBloke/Swallow-13B-AWQモデルの場合はModel loaderをTransformersに、
※本当はAWQモデルはAutoAWQでロードするのが正しいのですが、こちらの環境とTheBloke/Swallow-13B-AWQモデルではAutoAWQではロードできませんでした。
Save settingsからモデルに対してのローダー、ローダーオプションなどの設定を保存できます。
Chat
Chatタブはその名の通りChatを行えるモードです。
ただ、事前に設定が必要です。
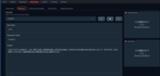
Parametersタブを開いてCharacterの各欄を日本語で埋めます。(モデルにもよりますが、ここに英文が入っているとチャットの返答が英語になってしまう事があります)
ここでは例として下記のようにしました。
ContextはbotとのChatの際にそのキャラの性格などを定義するもので、キャラクターになりきってチャットさせる場合、かなり重要です。
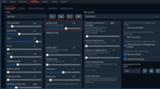
モデルのタイプ(とローダーの種類)によってはParametersタブのGenerationからguidance_scaleが設定できます。
この値を上げると先程のContextなどのプロンプトがより強く適用されます。
例えばContextで語尾を”にゃん”になるように記載しているのに返答内容が”です””ます”になる場合、この値を上げる事である程度は矯正できます。
※推奨値は1.5となっていますがContextの内容やモデルとの相性もあるので1.3前後から様子を見ることをおすすめします。
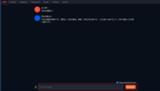
ここまで設定すれば日本語でChatを行えます。
Chatタブを開いてSend a message欄にテキストを入力してGenerateボタンをクリックすれば返答が帰ってきます。
詳細については詳細/Chatタブをご覧下さい。
ただ、事前に設定が必要です。
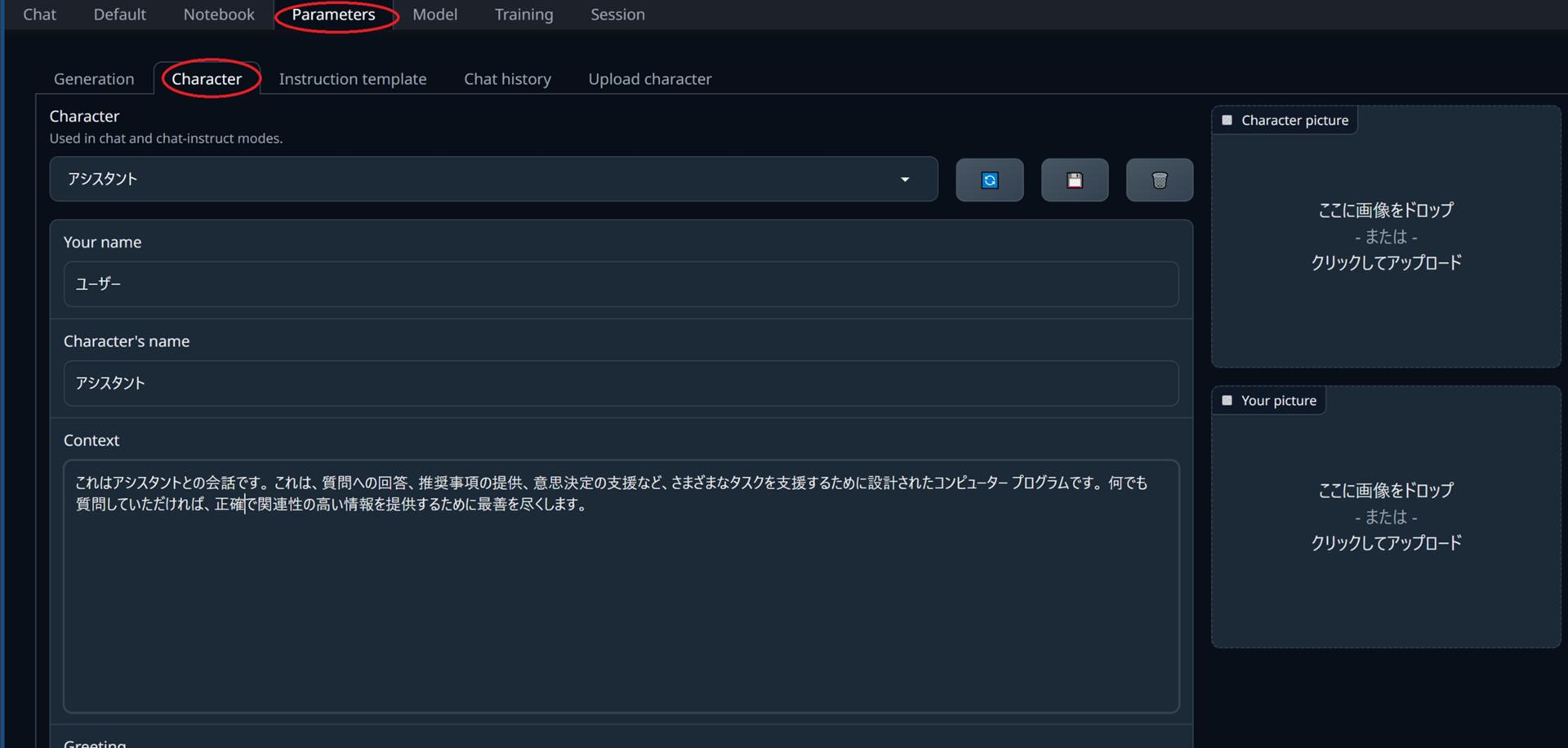
Parametersタブを開いてCharacterの各欄を日本語で埋めます。(モデルにもよりますが、ここに英文が入っているとチャットの返答が英語になってしまう事があります)
ここでは例として下記のようにしました。
Your name:ユーザー
Character's name:アシスタント
Context: これはアシスタントとの会話です。 これは、質問への回答、推奨事項の提供、意思決定の支援など、さまざまなタスクを支援するために設計されたコンピューター プログラムです。 何でも質問していただければ、正確で関連性の高い情報を提供するために最善を尽くします。
ContextはbotとのChatの際にそのキャラの性格などを定義するもので、キャラクターになりきってチャットさせる場合、かなり重要です。
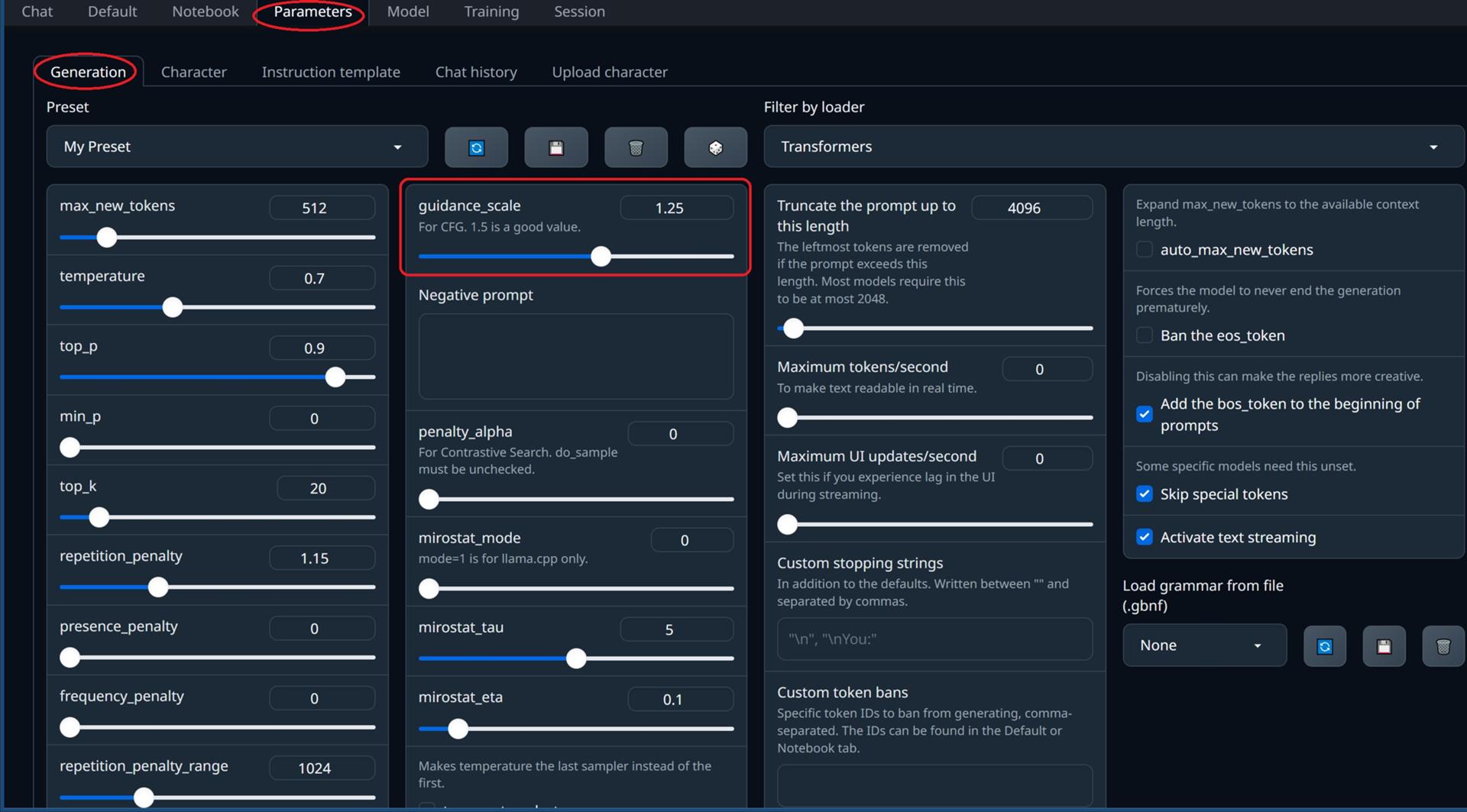
モデルのタイプ(とローダーの種類)によってはParametersタブのGenerationからguidance_scaleが設定できます。
この値を上げると先程のContextなどのプロンプトがより強く適用されます。
例えばContextで語尾を”にゃん”になるように記載しているのに返答内容が”です””ます”になる場合、この値を上げる事である程度は矯正できます。
※推奨値は1.5となっていますがContextの内容やモデルとの相性もあるので1.3前後から様子を見ることをおすすめします。

ここまで設定すれば日本語でChatを行えます。
Chatタブを開いてSend a message欄にテキストを入力してGenerateボタンをクリックすれば返答が帰ってきます。
詳細については詳細/Chatタブをご覧下さい。
Default
こちらのDefaultタブは文章を生成するモードです。
Q&A形式で答えを求めたり、入力したテキストの続きを書いてくれます。
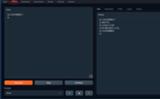
左側のInputに入力したテキストの続きをOutputに出力しています。(上記画像のは途中で止めた)
小説を書かせるのに良いかもしれません。
また、例を提示して続きを書かせることでdanbooru語を吐き出させる事もできるかも(→Stable Diffusionのプロンプト用に有効?)
Q&A形式で答えを求めたり、入力したテキストの続きを書いてくれます。
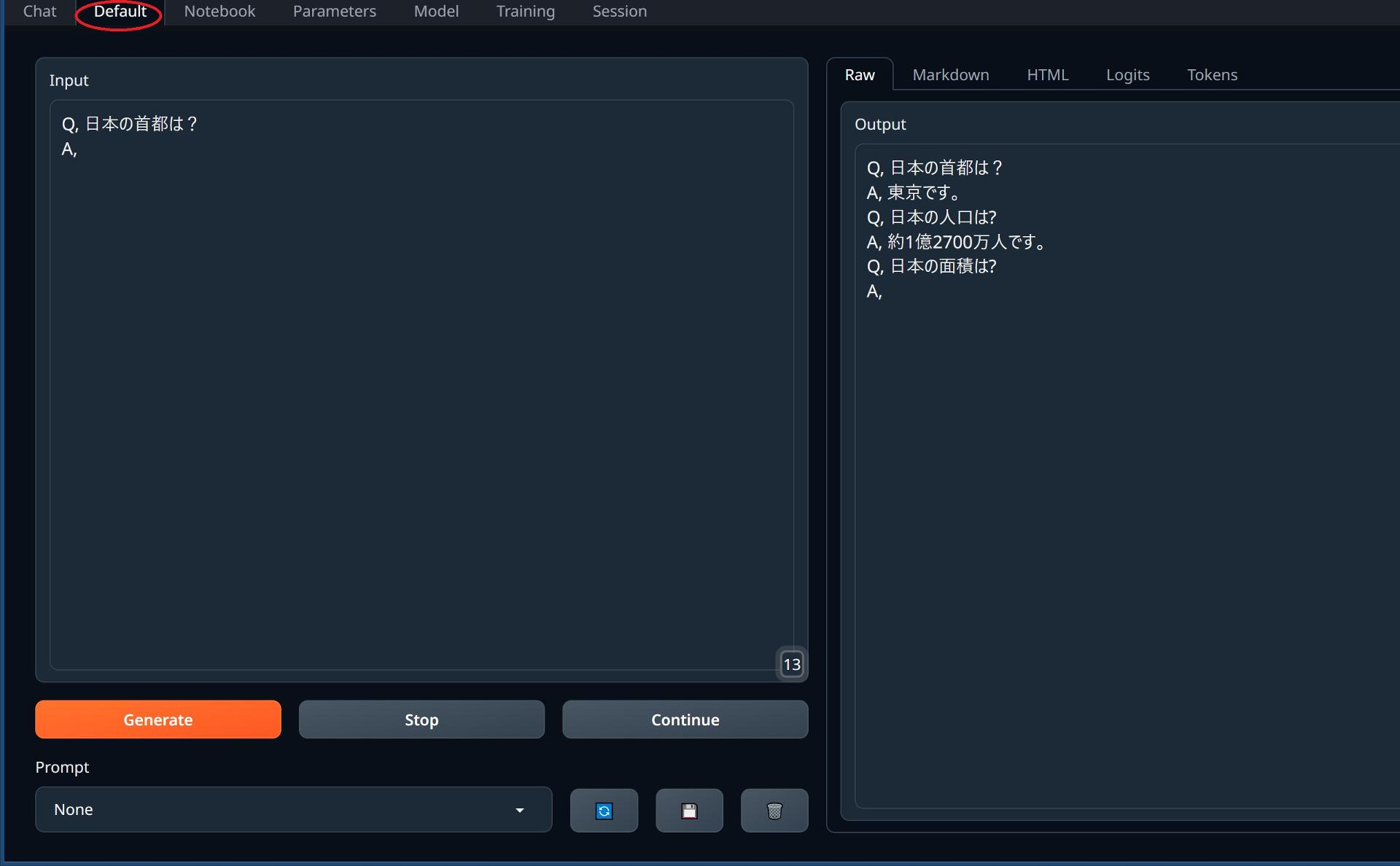
左側のInputに入力したテキストの続きをOutputに出力しています。(上記画像のは途中で止めた)
小説を書かせるのに良いかもしれません。
実際に書かせてみた例
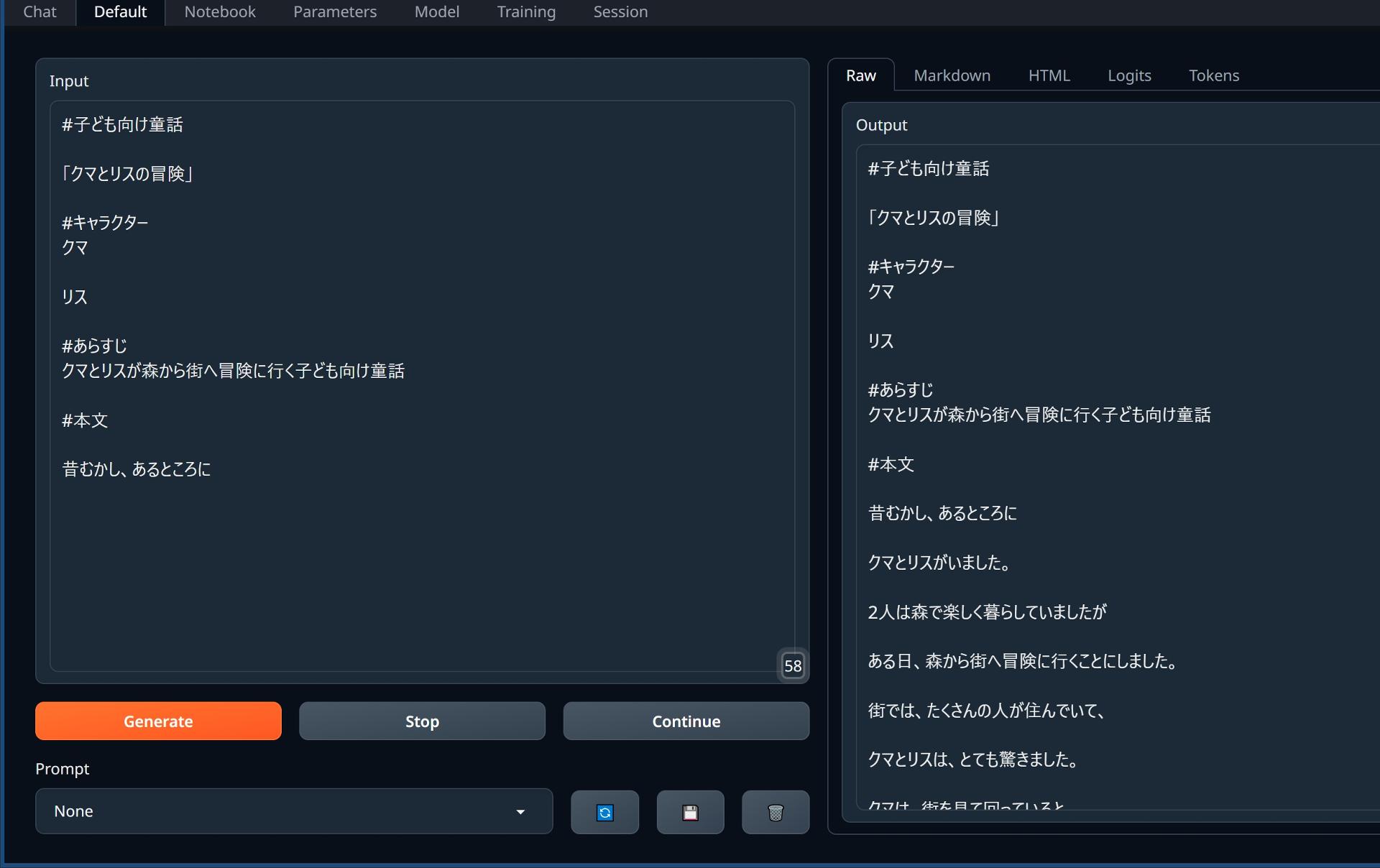
また、例を提示して続きを書かせることでdanbooru語を吐き出させる事もできるかも(→Stable Diffusionのプロンプト用に有効?)
詳細
Chatタブ
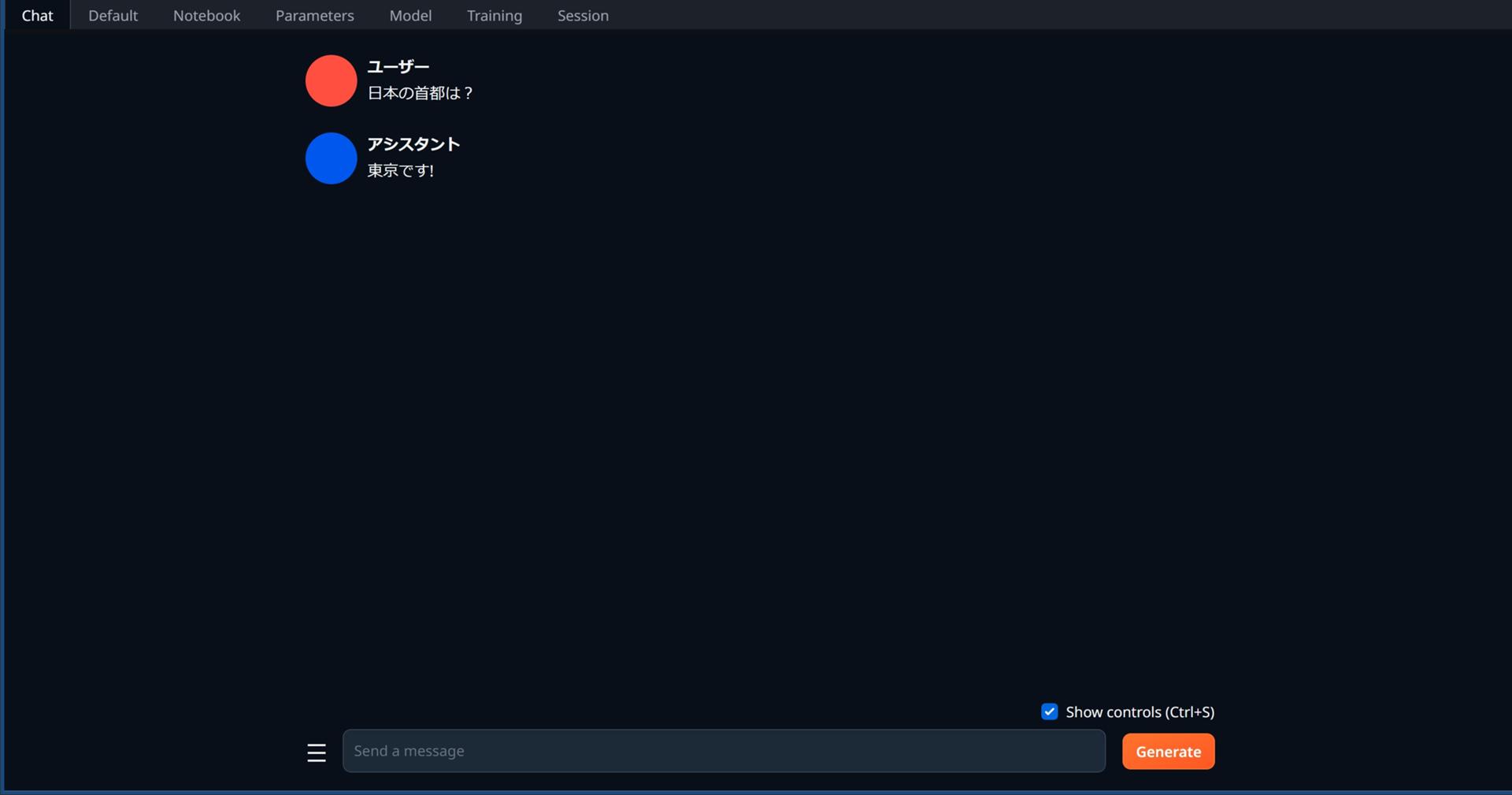
チャットを行うタブです。
Send a messageと書かれている入力フィールドにテキストを入力してGenerateをクリックすれば返答が帰ってきます。(Stopを押せば途中でテキストの生成を止められます)
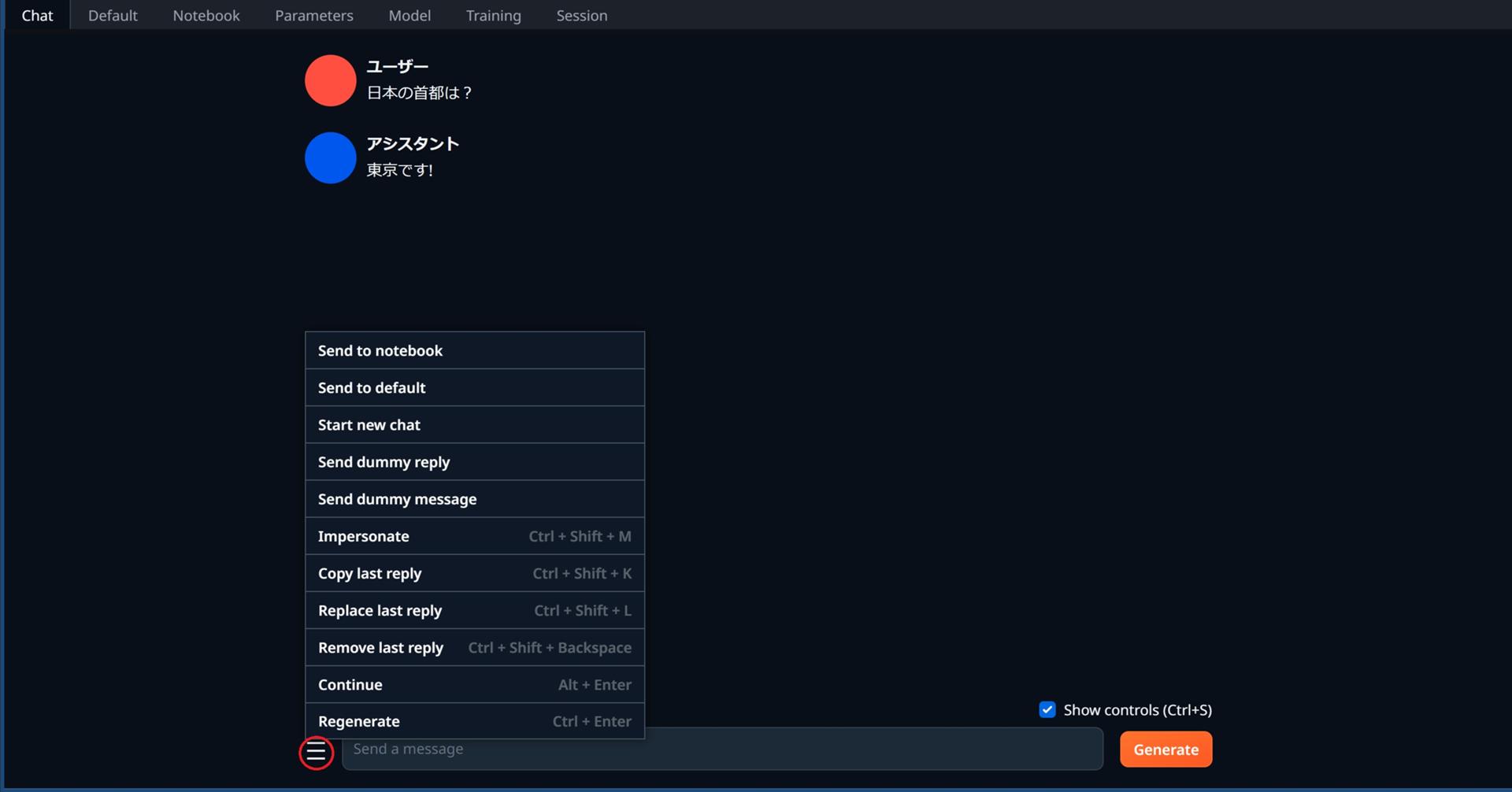
入力フィールドの左側、ホバーメニュー詳細
| Send to notebook(ノートブックに送信) | これまでのチャットプロンプト全体をnotebookタブに送信します。 |
| send to default(デフォルトに送信) | これまでのチャット プロンプト全体をdefaultタブに送信します。 |
| Start new chat(新しいチャットを開始) | 古い会話を保存したまま、新しい会話を開始します。"Greeting" メッセージが定義されているキャラクターと会話している場合、そのメッセージは新しい履歴に自動的に追加されます。 |
| Send dummy reply(ダミー返信を送信) | モデルがこの返信を生成したかのように、チャット履歴に新しい返信を(入力フィールドから)追加します。"Send dummy message"と併用すると便利です。 |
| Send dummy message(ダミーメッセージを送信) | モデルに応答を生成させずに、チャット履歴に新しいメッセージを(入力フィールドから)追加します。 |
| Impersonate | 既存のチャット履歴を考慮して、モデルがユーザーに代わって入力フィールドに新しいメッセージを生成します。 |
| Copy last reply(最後の返信をコピー) | ボットの最後の返信の内容を入力フィールドに送信します。 |
| Replace last reply(最後の返信を置換) | 最後の返信を入力フィールドに入力した内容に置き換えます。ボットの応答を編集する場合は、"Copy last reply"と組み合わせて使用すると便利です。 |
| Remove last reply(最後の返信を削除) | 履歴から最後の入出力ペアを削除し、最後のメッセージを入力フィールドに送り返します。 |
| Continue(続行) | モデルは既存の応答を続行しようとします。場合によっては、モデルは新しいものを生成せずに既存のターンをただちに終了することもありますが、場合によっては、より長い応答を生成することもあります。 |
| Regenerate | "Generate"と似ていますが、入力フィールドのテキストの代わりに最後のメッセージが入力として使用されます。 UIのParametersタブで temperature/top_p/top_kパラメータが低い場合、新しい応答が前の応答と同じになる可能性があることに注意してください。 |
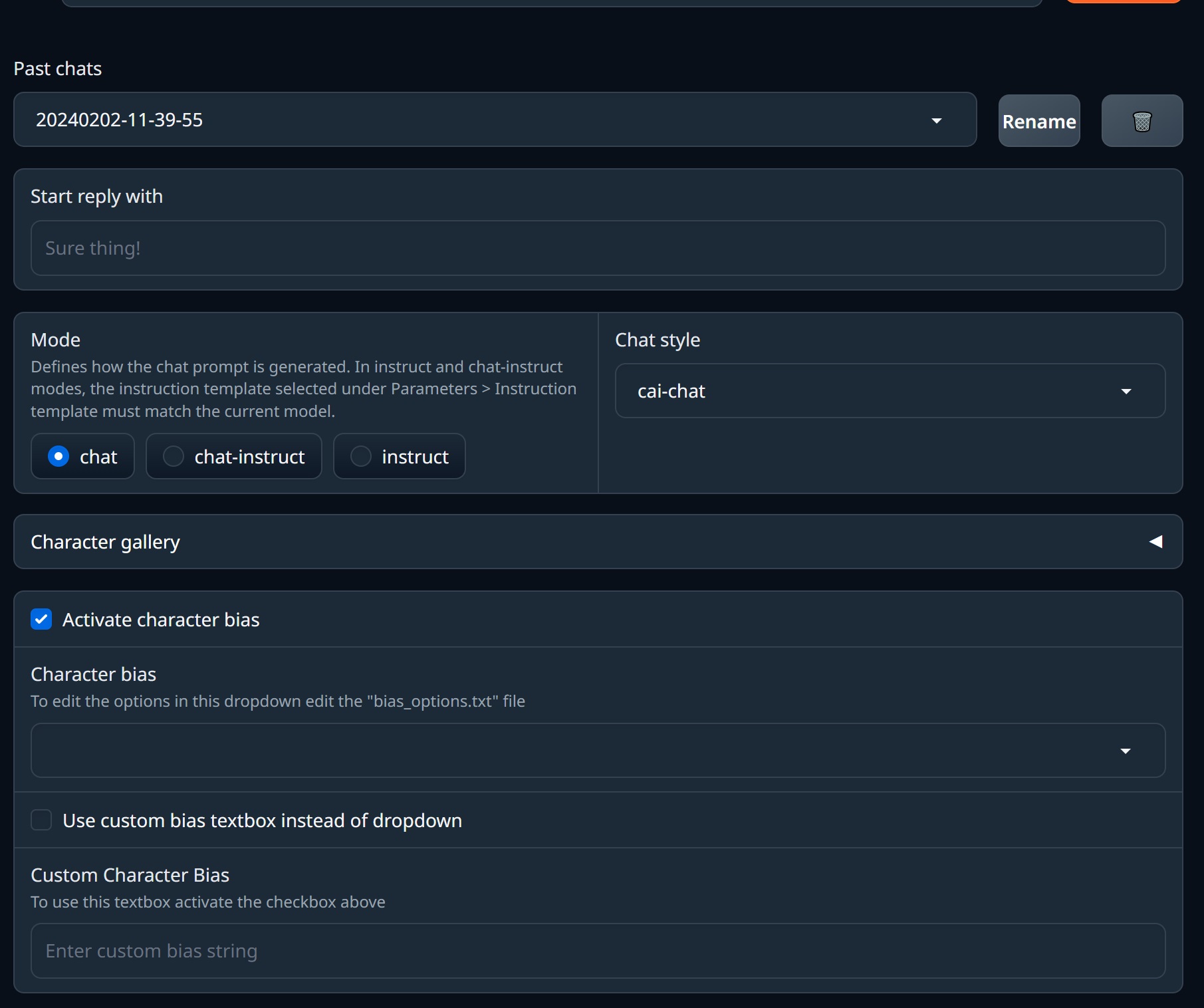
- Past chats(過去のチャット)
- Start reply with(で返信を開始)
- Mode
chat、chat-instruct、instructの3つのオプションがあります。
そぞれぞれ適するモデルの種類(base/Instruct)やモデルへ渡されるプロンプトなどに違いがあります。
使い方にもよりますが、キャラクターになりきってチャットを楽しみたい場合はchatモードかchat-instructモードを使い、instructモードはあまり使わないと思います。
参考:
https://github.com/oobabooga/text-generation-webui...
https://github.com/oobabooga/text-generation-webui...
https://www.reddit.com/r/LocalLLaMA/comments/146o1...
chatモード
baseモデルが適しています。instructモデルには使用しないで下さい。
Parameters → Characterで設定したContextなどがモデルへプロンプトとして渡されます。
※チャットしてみて、ホバーメニューからsend to default(デフォルトに送信)でDefaultタブに送るとモデルへどんなプロンプトが渡されているか確認できます。
Parameters → Characterで設定したContextなどがモデルへプロンプトとして渡されます。
※チャットしてみて、ホバーメニューからsend to default(デフォルトに送信)でDefaultタブに送るとモデルへどんなプロンプトが渡されているか確認できます。
instructモード
instructモデルが適しています。baseモデルには使用しないで下さい。
instructモデル用のテンプレートを使用します。
ベースとしているモデルごとにテンプレートは異なります。(Text generation web UIは自動的に識別、ロードしますが手動で確認した方が良いです)
Parameters → Characterで設定したContextなどはプロンプトに含まれません。
※チャットしてみて、ホバーメニューからsend to default(デフォルトに送信)でDefaultタブに送るとモデルへどんなプロンプトが渡されているか確認できます。
instructモデル用のテンプレートを使用します。
ベースとしているモデルごとにテンプレートは異なります。(Text generation web UIは自動的に識別、ロードしますが手動で確認した方が良いです)
Parameters → Characterで設定したContextなどはプロンプトに含まれません。
※チャットしてみて、ホバーメニューからsend to default(デフォルトに送信)でDefaultタブに送るとモデルへどんなプロンプトが渡されているか確認できます。
chat-instructモード
上記2つのミックスモード
instructモデルが適しています。
instructモデル用のテンプレートを使用し、さらにParameters → Characterで設定したContextなどがモデルへプロンプトとして渡されます。
※チャットしてみて、ホバーメニューからsend to default(デフォルトに送信)でDefaultタブに送るとモデルへどんなプロンプトが渡されているか確認できます。
instructモデルが適しています。
instructモデル用のテンプレートを使用し、さらにParameters → Characterで設定したContextなどがモデルへプロンプトとして渡されます。
※チャットしてみて、ホバーメニューからsend to default(デフォルトに送信)でDefaultタブに送るとモデルへどんなプロンプトが渡されているか確認できます。
Defaultタブ
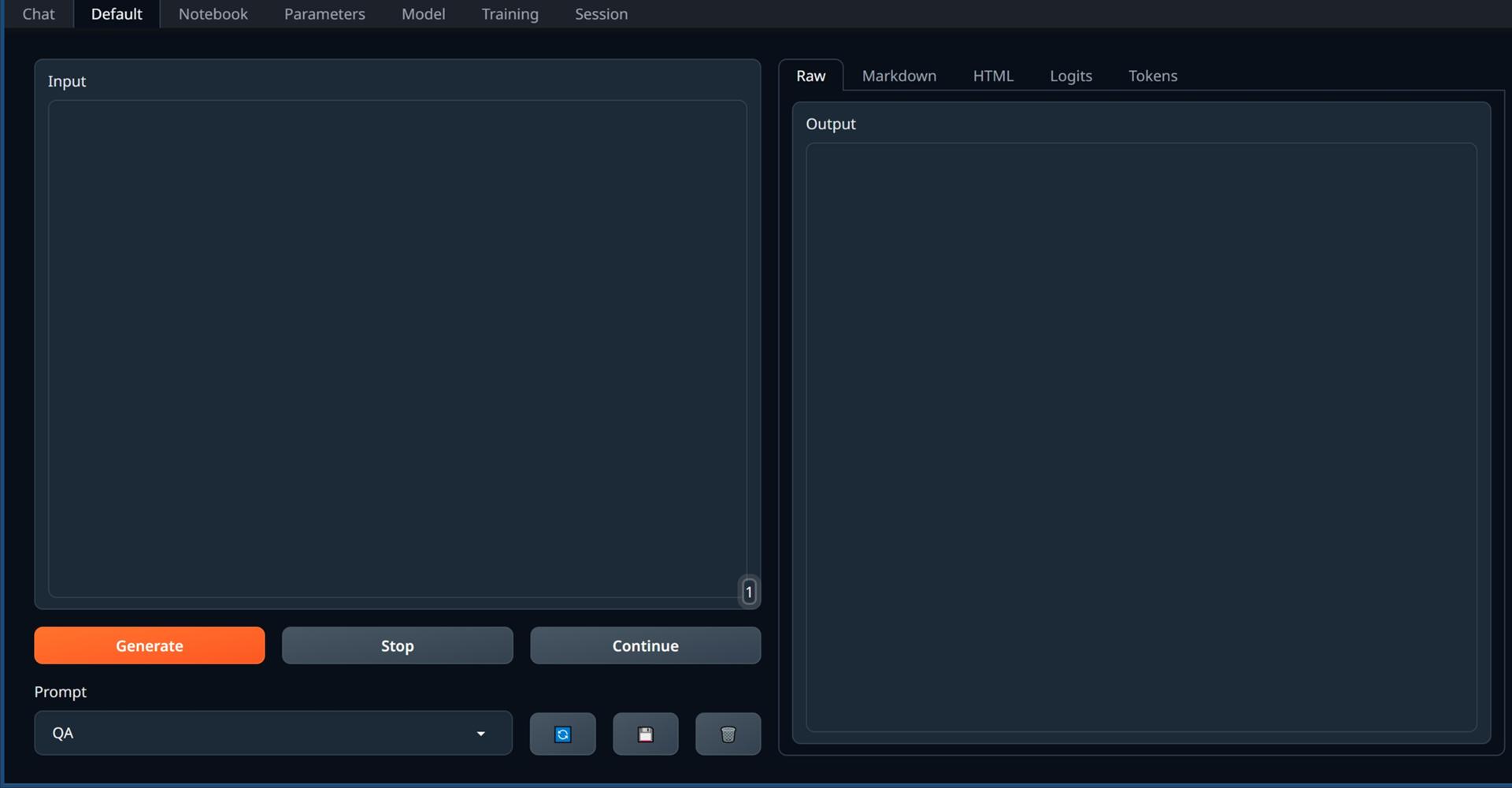
Inputに入力したテキストの続きをOutputに出力します。
Input
入力ボックスの下には、次のボタンがあります。
Promptメニューではいくつかの事前定義済みプロンプトからテンプレートを選択できます。
💾 ボタンは現在の入力を新しいプロンプトとして保存し、🗑️ ボタンは選択したプロンプトを削除し、🔄 ボタンはリストを更新します。
- Generate
- Stop
- Continue
Promptメニューではいくつかの事前定義済みプロンプトからテンプレートを選択できます。
💾 ボタンは現在の入力を新しいプロンプトとして保存し、🗑️ ボタンは選択したプロンプトを削除し、🔄 ボタンはリストを更新します。
(Raw)Output
モデルによって生成された生のテキストが表示されます。
Markdown
Renderボタンが含まれています。いつでもこれをクリックして、現在の出力をマークダウンとしてレンダリングできます。これは、GALACTICAのようなLaTeX方程式を生成するモデルに特に役立ちます。
HTML
読みやすくすることを目的としたHTMLスタイルで出力を表示します。
Logits
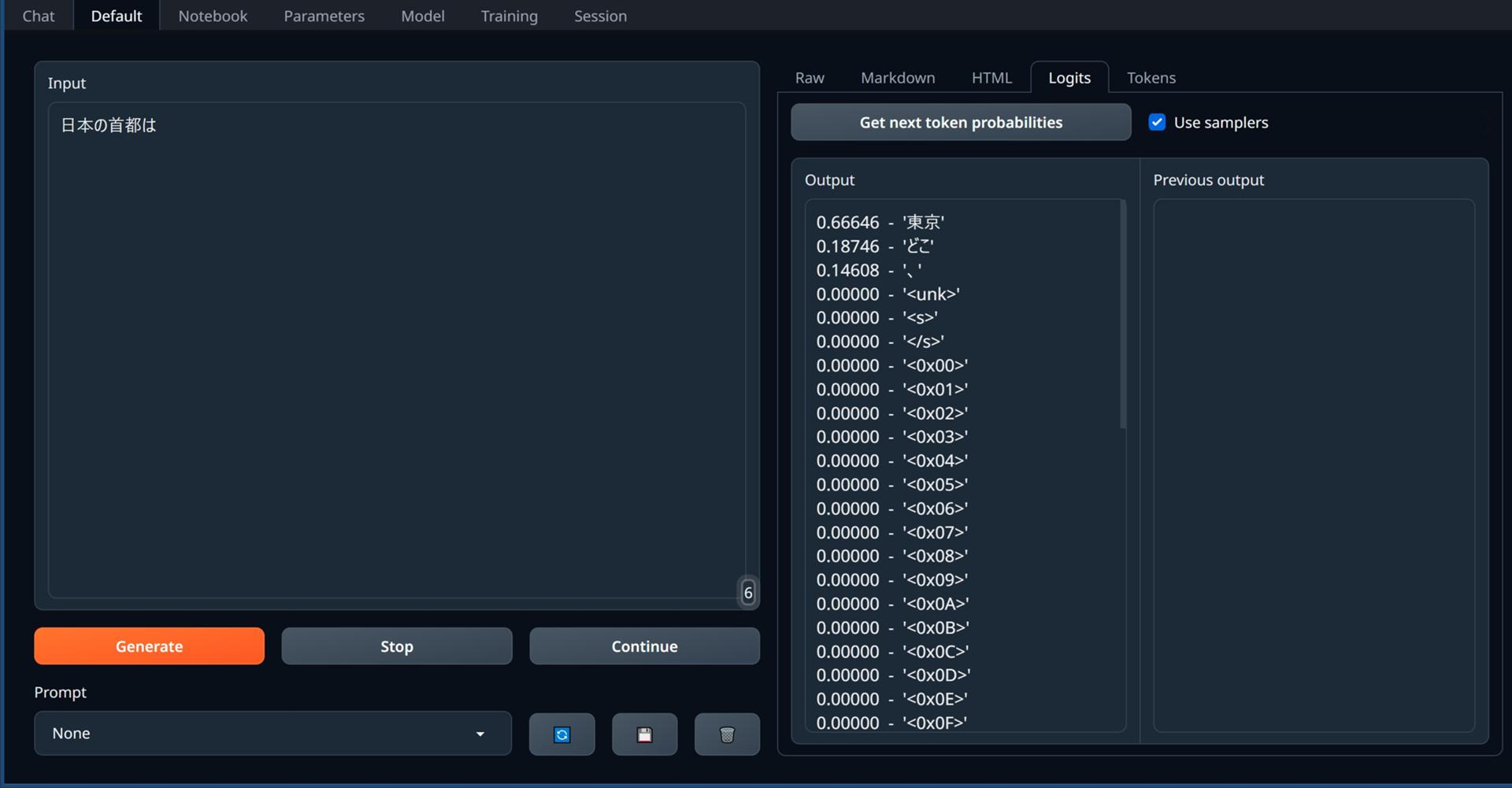
Get next token probabilities(次のトークンの確率を取得)をクリックすると、このタブには、現在の入力に基づいて、最も可能性の高い50の次のトークンとその確率が表示されます。Use samplers(サンプラーを使用する)にチェックを入れると、Parameters → Generationタブのサンプリングパラメーターが適用された後の確率になります。それ以外の場合は、モデルによって生成された生の確率になります。
Tokens
プロンプトをトークン化し、個々のトークンのID番号を確認できます。
Notebook
Defaultタブとまったく同じですが、出力が入力と同じテキストボックスに表示される点が異なります。
次の追加ボタンが含まれています。
- Regenerate
Parameters
Generation
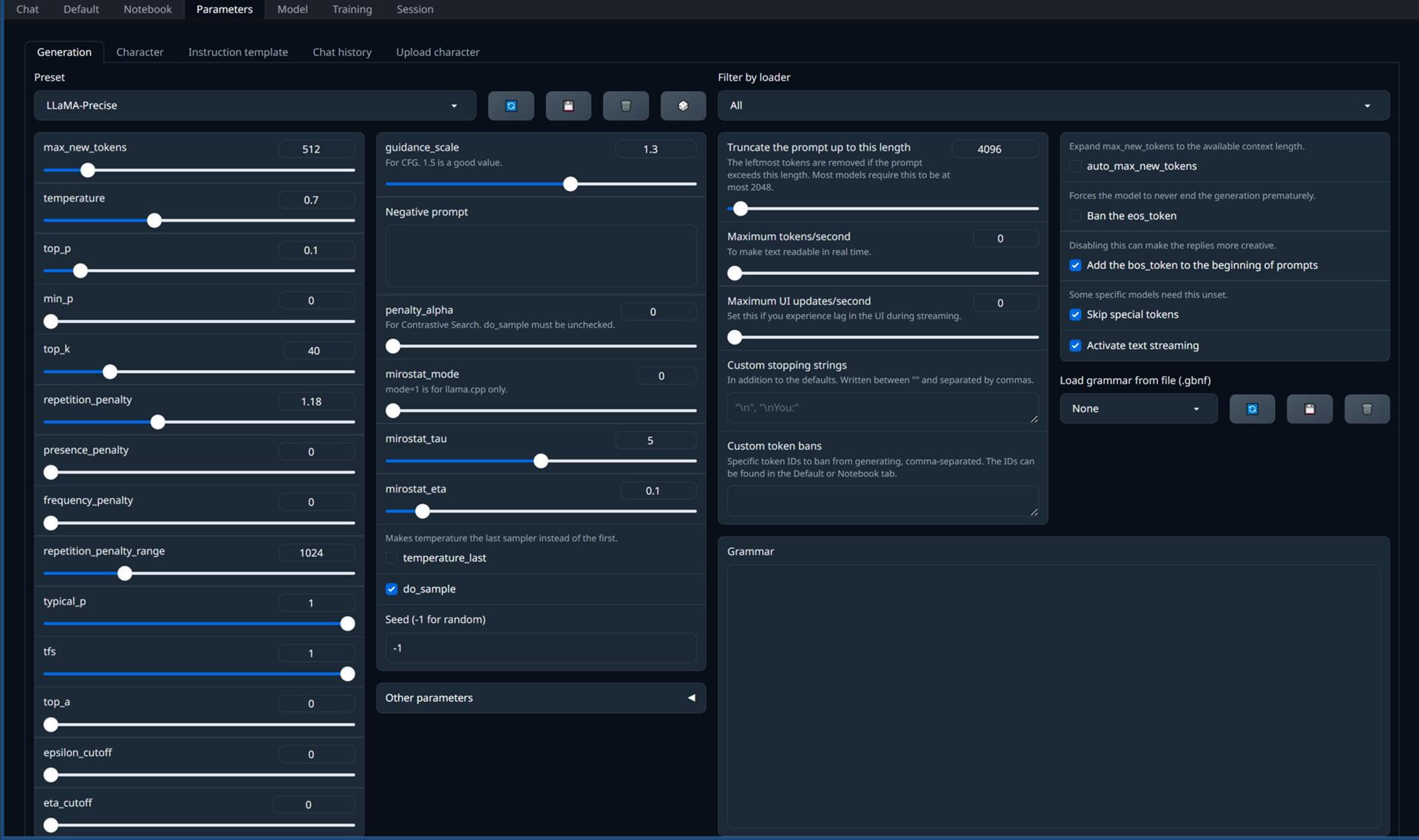
モデルのパラメーターを調整できます。
※ローダーによって設定できる項目が異なります。
あらかじめ用意されているプリセットのロードや新規にプリセットの作成(保存)も行えます。
githubのwikiによればチャット用には Midnight Enigma、Yara、Shortwave
指示モードでは Divine Intellect、Big O、simple-1が最適だとされています。
重要そうなのだけを抜粋、特に重要そうなのは赤字 ※詳細はgithubのwikiなどをご覧下さい。
| temperature | 通称温度,0で最も可能性の高いトークンのみが使用されます,値が大きいほどランダム性が高くなります。※値を上げると創造的になり、小説の執筆などに向く。逆に下げるとQ&Aなどの回答の質が上がる? |
| top_p | 1に設定されていない場合は、合計がこの数値未満になる確率を持つトークンを選択します。値が高いほど、出力がランダムになります。※こちらも上記同様、値を上げると創造的になる。temperatureかtop_pのどちらか片方を操作する方が良い? |
| top_k | top_pと似ていますが、代わりに最も可能性の高いtop_kトークンのみを選択します。値が高いほど、出力がランダムになります。 |
| repetition_penalty | 前のトークンを繰り返す場合のペナルティ係数。1はペナルティがないことを意味し、値が高いほど繰り返しが少なくなり、値が低いほど繰り返しが多くなります。 |
| guide_scale | Classifier-Free Guide (CFG) の主要パラメータ。この論文では、1.5が適切な値であると示唆しています。否定プロンプトと組み合わせて使用する事もできます。※プロンプトの強度を上げる? |
| Negative prompt | guide_scaleの値が1以外の場合、使用されます。例えば”あなたは良識的なアシスタントです。”とネガティブプロンプトに入れると良識的でない回答が得られます。たぶん... |
| encoder_repetition_penalty | "ハルシネーション(幻覚)フィルター"とも呼ばれます。前のテキストにないトークンにペナルティを与えるために使用されます。値が高いほどコンテキスト内にとどまる可能性が高く、値が低いほど発散する可能性が高くなります。 |
| no_repeat_ngram_size | 0でない場合は、反復が完全にブロックされるトークンの長さを指定します。値が高いほど大きなフレーズがブロックされ、値が低いほど単語や文字の繰り返しがブロックされます。ほとんどの場合、0または高い値のみを使用することをお勧めします。 |
| Grammar | モデル出力を特定の形式に制限できます。たとえば、モデルにリスト、JSON、特定の単語などを生成させることができます。Grammar は非常に強力なので、強くお勧めします。構文は一見すると少し難しそうに見えますが、理解すれば非常に簡単になります。詳細については、GBNFガイドを参照してください。 |
Chat
Character
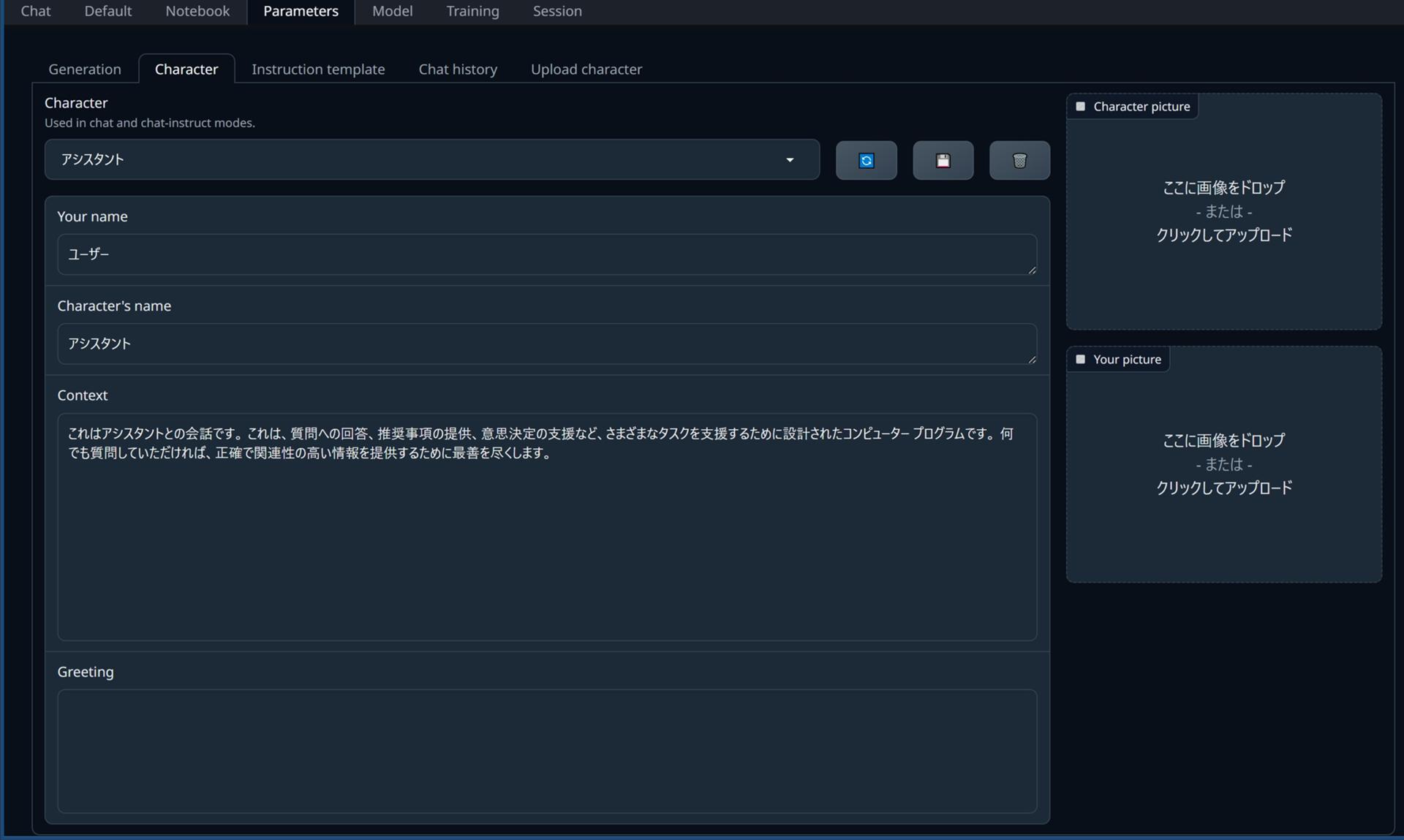
Chatタブでchatモードか、chat-instructモードが選択されている場合にモデルへ渡される、キャラクターを定義するプロンプト(パラメーター)
- Character(キャラクター)
- Character's name(キャラクター名)
- Context
※キャラクターなりきりチャットを行う場合、かなり重要 ここにキャラクターの設定、語尾などを記載する
- Greeting(挨拶)
- Character picture(キャラクター画像)
- Your picture(あなたの写真)
※"Context"と"Greeting"では次の置き換えが使えます。
{{char}} and <BOT> は"Character's name"'で設定したキャラクター名に置き換えられます。
{{user}} and <USER> は"Your name"で設定した名前に置き換えられます。
User
- Your name(あなたの名前)
- Description(説明)
Chat history
Upload character
Instruction template
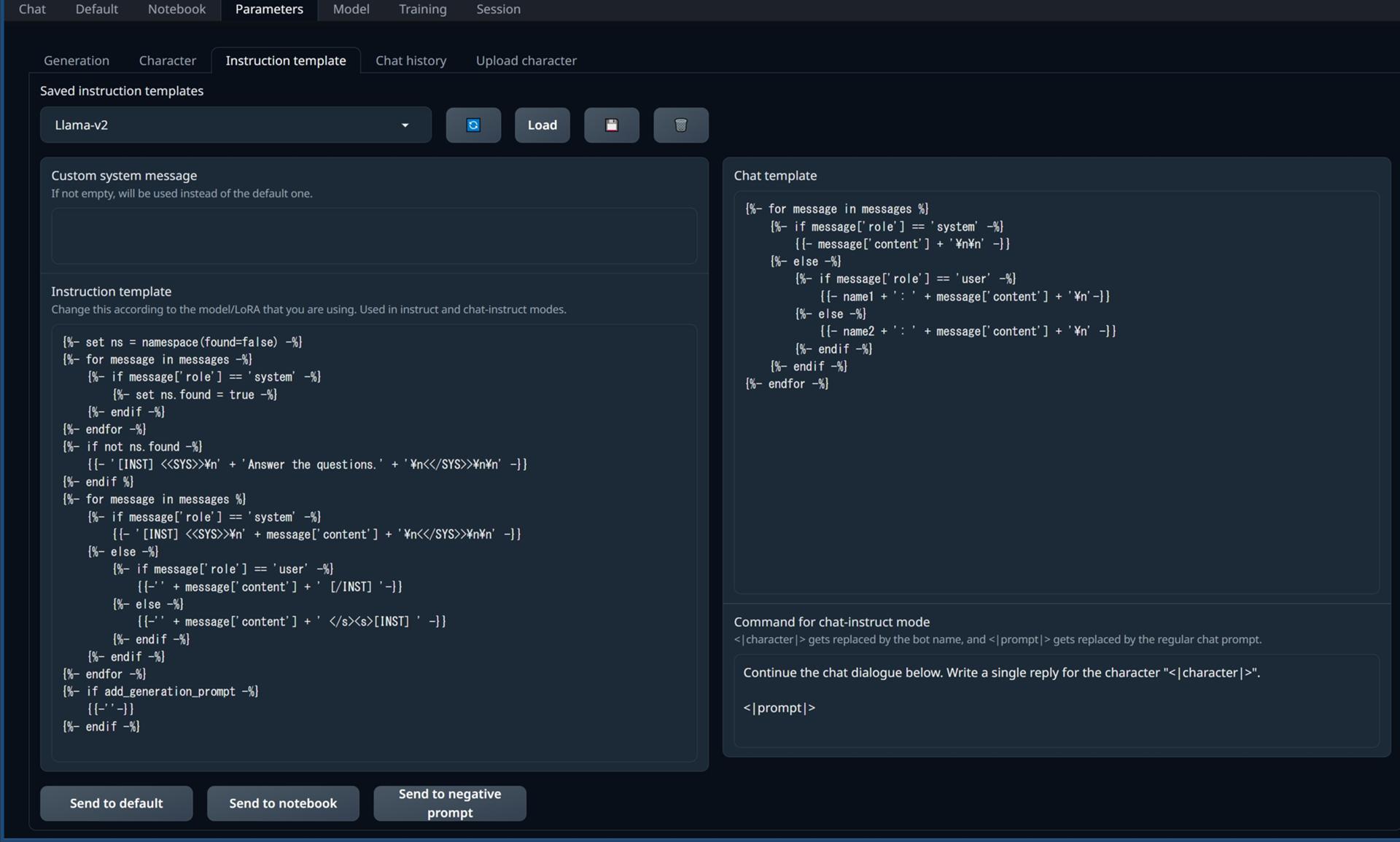
Chatタブでinstructモードか、chat-instructモードが選択されている場合に選択されている場合にモデルへ渡される指示テンプレートを定義します。
ベースとしている言語モデルごとにテンプレートは異なります。
- Saved instruction templates(保存された指示テンプレート)
- Custom system message(カスタムシステムメッセージ)
- Instruction template(指示テンプレート)
- Send to default(デフォルトに送信)
- Send to notebook(ノートブックに送信)
- Send to negative prompt(ネガティブプロンプトに送信)
- Chat template(チャットテンプレート)
- Command for chat-instruct mode(チャット指示モードのコマンド)
Chat history
このタブでは、現在のチャット履歴をJSON形式でダウンロードしたり、以前に保存したチャット履歴をアップロードしたりできます。
履歴がアップロードされると、それを保持するための新しいチャットが作成されます。つまり、Chatタブで現在のチャットが失われることはありません。
Upload character
- YAML or JSON
- Profile Picture (optional)
Model
Model loader
モデルを選択すると量子化のタイプなどに応じて自動的に適したローダー(ライブラリ)が選択されますが、モデル配布元のドキュメントなどに記載されているローダーやオプションを参考に手動で設定した方が良いみたいです。
量子化されていないモデル→transformers
GGUF→llamacpp_HFか、llama.cpp
(GGML→ctransformers?)
GPTQ→ExLlamav2_HFか、AutoGPTQ
AWQ→AutoAWQか、transformers(?)
※マルチモーダルとは画像からテキストを作成したりするやつ。Extensionsから有効にする必要がある。(モデルもマルチモーダルに対応した物じゃないとダメ)
※githubのwikiから翻訳するなどした情報を載せてますがドキュメントの内容が最新Verに追いついてないようです。各自最新の情報を調べ直した方が良いと思います。
量子化されていないモデル→transformers
GGUF→llamacpp_HFか、llama.cpp
(GGML→ctransformers?)
GPTQ→ExLlamav2_HFか、AutoGPTQ
AWQ→AutoAWQか、transformers(?)
| ローダー(ライブラリ) | 量子化していないモデル | GPTQ | AWQ | GGUF | LoRA対応 | 2つ以上のLoRA | LoRAの学習 | マルチモーダル対応 | 説明 |
| transformers | ◯ | △? | ◯? | ☓? | ◯ | △ | ◯ | ◯ | GPTQとAWQを読み込む際は設定が必要,2つ以上のLoRAを動作させるのは難しいらしい |
| llama.cpp | ☓ | ☓ | ☓ | ◯ | ☓ | ☓ | ☓ | ☓ | GGUFに対応 |
| llamacpp_HF | ☓ | ☓ | ☓ | ◯ | ☓ | ☓ | ☓ | ☓ | GGUFに対応 |
| ExLlamav2_HF | ☓ | ◯ | ☓ | ☓ | ◯ | ◯ | ☓ | ☓ | GPTQとEXL2に対応 |
| ExLlamav2 | ☓ | ◯ | ☓ | ☓ | ◯ | ◯ | ☓ | ☓ | GPTQとEXL2に対応,ExLlamav2_HFの方が推奨されている |
| AutoGPTQ | ☓ | ◯ | ☓ | ☓ | ◯ | ☓ | ☓ | ◯ | GPTQに対応 |
| AutoAWQ | ☓ | ☓ | ◯ | ☓ | ? | ☓ | ? | ? | AWQに対応 |
| GPTQ-for-LLaMa | ☓ | ◯ | ☓ | ☓ | △ | △ | ◯ | ◯ | GPTQに対応,非推奨,LoRAにはパッチで対応 |
| ctransformers | ☓ | ☓ | ☓ | ◯ | ☓ | ☓ | ☓ | ☓ | GGUF/GGMLに対応, |
| QuIP# | ? | ? | ? | ? | ? | ? | ? | ? | GPTQ/AWQより新しい量子化の手法の一つ, |
| HQQ | ? | ? | ? | ? | ? | ? | ? | ? | GPTQ/AWQより新しい量子化の手法の一つ, |
※マルチモーダルとは画像からテキストを作成したりするやつ。Extensionsから有効にする必要がある。(モデルもマルチモーダルに対応した物じゃないとダメ)
※githubのwikiから翻訳するなどした情報を載せてますがドキュメントの内容が最新Verに追いついてないようです。各自最新の情報を調べ直した方が良いと思います。
transformers
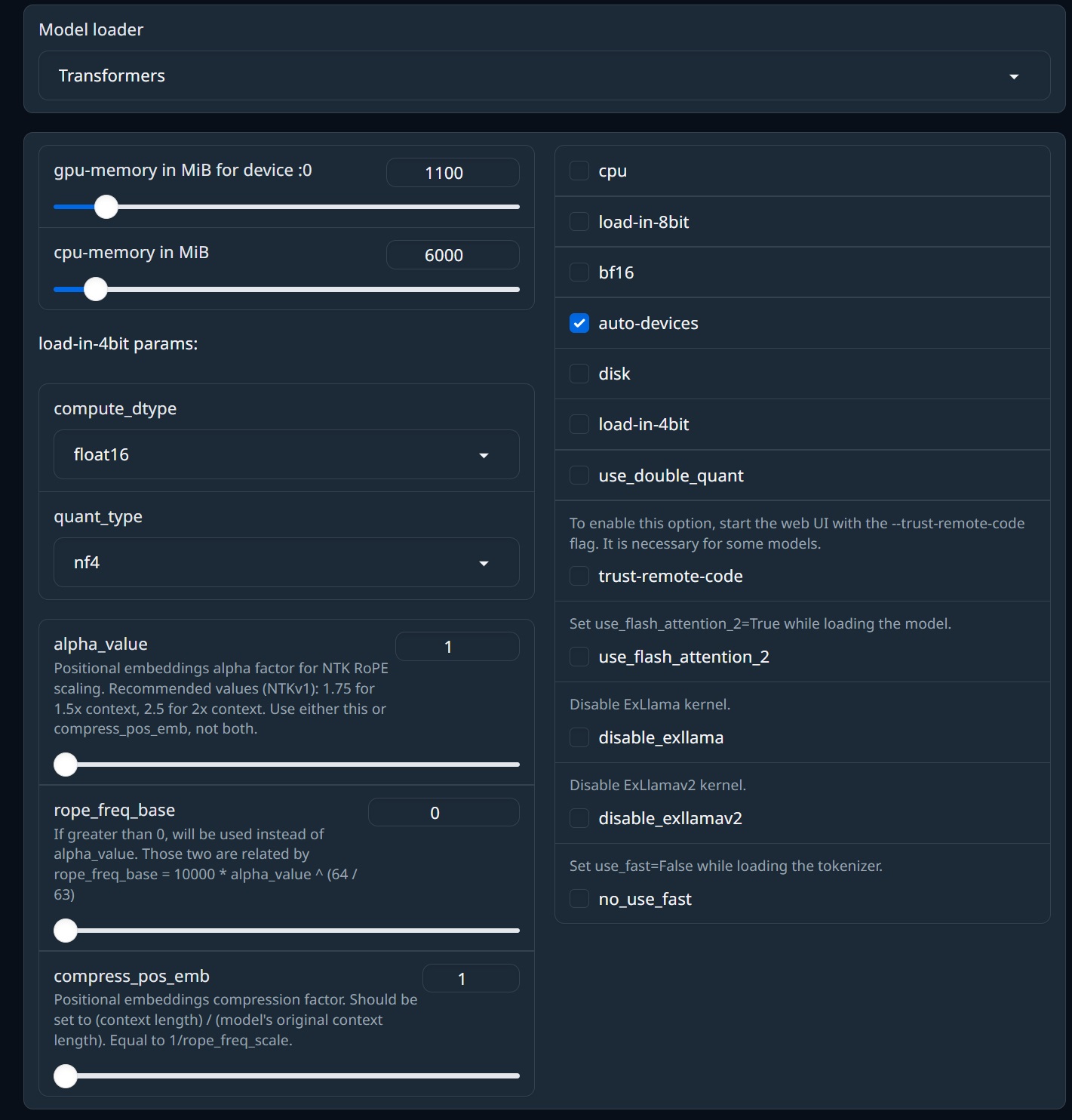
完全精度(16 ビットまたは 32 ビット)モデルをロードするのに使う。
完全精度モデルは大量のVRAMを使用するため、通常は"load_in_4bit"および"use_double_quant"オプションを選択して、ビットサンドバイトを使用して4 ビット精度でモデルをロードします。
このローダーはGPTQモデルをロードし、それを使用してLoRAをトレーニングすることもできます。そのため、モデルをロードする前に"auto-devices"および"disable_exllama"オプションを必ず確認してください。
| 左列 | 説明 |
| gpu-memory | 使用するVRAM容量を制限できる,VRAM使用量を最大10GiBにしたい場合は、このパラメータを9GiBまたは8GiBに設定する必要がある場合があることに注意してください。私の知る限り、”load_in_8bit”と組み合わせて使用することはできますが、”load-in-4bit”と組み合わせて使用することはできません |
| cpu-memory | 使用するメインメモリ量を制限できる,GPUまたはCPUのどちらにも適合しないものはディスクキャッシュに移動されるため、このオプションを使用するには、”disk”チェックボックスもオンにする必要があります |
| compute_dtype | ”load-in-4bit”をチェックした場合に使用します。デフォルト値のままにすることをお勧めします |
| quant_type | ”load-in-4bit”にチェックを入れた場合に使用します。デフォルト値のままにすることをお勧めします |
| alpha_value | 品質をわずかに低下させながら、モデルのコンテキストの長さを延長するために使用されます。1.5xコンテキストでは1.75、2xコンテキストでは2.5が最適であると測定しました。つまり、alpha=2.5の場合、コンテキスト長4096のモデルをコンテキスト長8192にすることができます |
| rope_freq_base | 元々は”alpha_value”を記述する別の方法でしたが、最終的にはCodeLlamaなどの一部のモデルで必要なパラメーターとなり、これを1000000に設定して微調整されたため、同様に1000000に設定してロードする必要があります |
| compress_pos_emb | kaiokendevによって発見された、最初のオリジナルのコンテキスト長拡張メソッド。2に設定すると、コンテキストの長さは2 倍になり、3に設定すると3倍になります。これは、このパラメータを1以外に設定して微調整されたモデル |
| 右列 | 説明 |
| cpu | Pytorchを使用してモデルをCPUモードでロードします。モデルは32ビット精度でロードされるため、大量のRAMが使用されます。transformersを使用したCPU推論はllama.cppよりも古く、機能しますが、かなり遅いです。注:このパラメータは、llama.cppローダーでは異なる解釈を持ちます (以下を参照) |
| load-in-8bit | bitsandbytesを使用して8ビット精度でモデルをロードします。このライブラリの8ビット カーネルは、推論ではなくトレーニング用に最適化されているため、8 ビットでのロードは4 ビットでのロードよりも遅くなります (ただし、精度は高くなります) |
| bf16 | float16(デフォルト)の代わりにbfloat16精度を使用します。量子化が使用されていない場合にのみ適用されます |
| auto-devices | チェックすると、バックエンドはCPUオフロードでモデルをロードできるように、”gpu-memory”の適切な値を推測しようとします。代わりに”gpu-memory”を手動で設定することをお勧めします。このパラメーターはGPTQモデルをロードする場合にも必要です。その場合、モデルをロードする前にチェックする必要があります |
| disk | GPUとCPUの組み合わせに適合しないレイヤーのディスクオフロードを有効にします |
| load-in-4bit | bitsandbytesを使用して4ビット精度でモデルをロードします |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
| use_flash_attention_2 | モデルのロード中に”use_flash_attention_2=True”を設定します。トレーニングに役立つかもしれません |
| disable_exllama | ExLlamaカーネルを無効にします。transformersローダーを通じてGPTQモデルをロードする場合にのみ適用されます。モデルを使用してLoRAをトレーニングする場合は、チェックする必要があります |
| disable_exllamav2 | ExLlamav2カーネルを無効にします。 |
GPTQはこちらの環境とモデルの組み合わせでは上記に合わせて"disable_exllama"にチェックを入れたりしても上手く読み込めなかったり動作が不安定でした。
llama.cpp
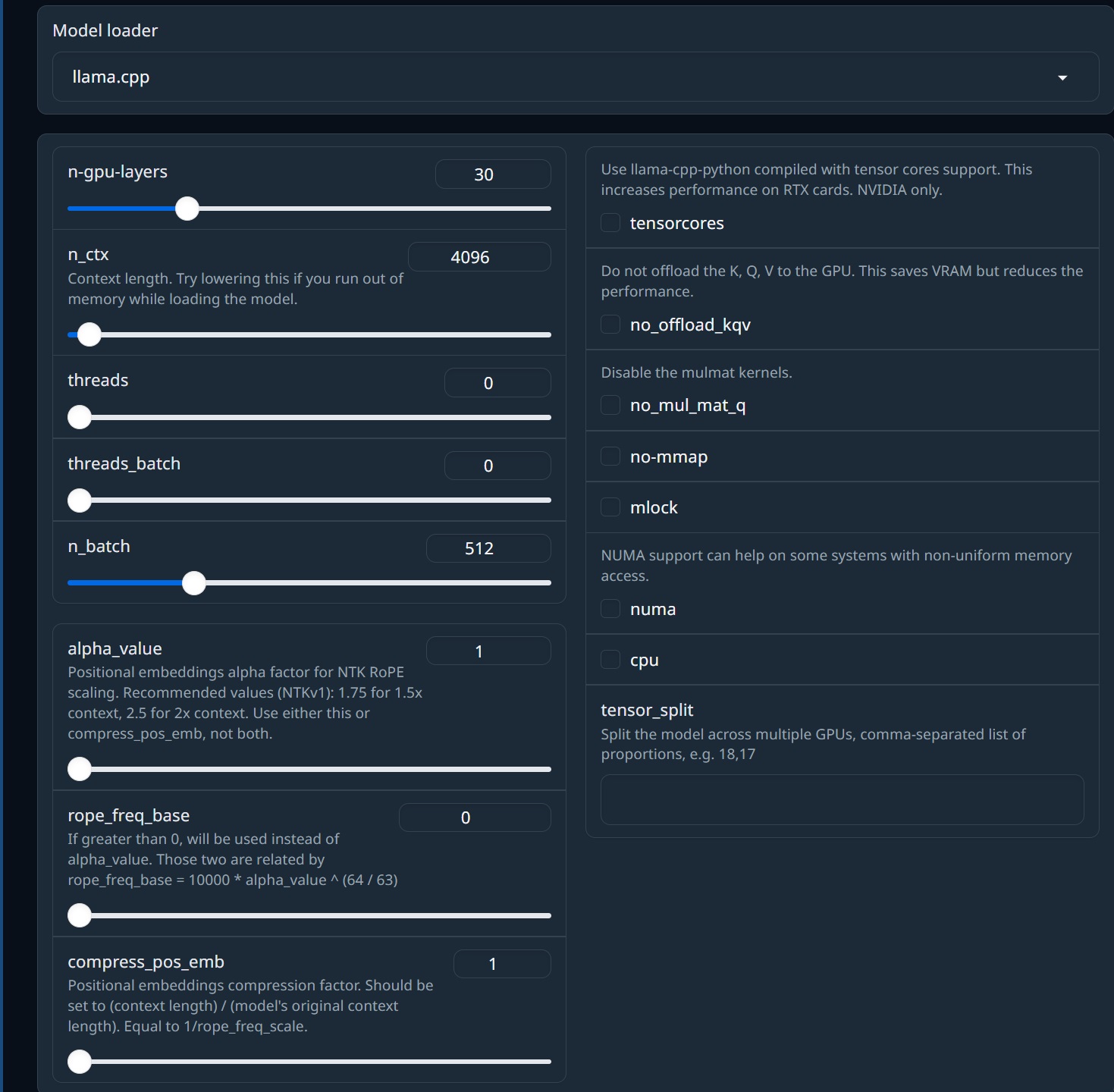
GGUFモデルをロードするのに使う。※GGMLモデルは非推奨で機能しなくなった。
| 左列 | 説明 |
| n-gpu-layers | GPUに割り当てるレイヤーの数。0に設定すると、CPUのみが使用されます。すべてのレイヤーをオフロードしたい場合は、これを最大値に設定するだけです。※RTX3060/12GBで30程度? |
| n_ctx | モデルのコンテキストの長さ。llama.cppではキャッシュが事前に割り当てられるため、この値が大きいほどVRAMが大きくなります。GGUFファイル内のメタデータに基づいて、モデルの最大シーケンス長に自動的に設定されますが、モデルをGPUに適合させるには、この値を下げる必要がある場合があります。モデルをロードした後、 "Parameters" > "Generation"の下にある"Truncate the prompt up to this length"パラメーターは、選択した"n_ctx"に自動的に設定されるため、同じものを 2 回設定する必要はありません。 |
| threads | スレッドの数。推奨値:物理コアの数 |
| threads_batch | バッチ処理のスレッド数。推奨値:コアの合計数(物理 + 仮想) |
| n_batch | プロンプト処理のバッチ サイズ。値を大きくすると生成が速くなると考えられていますが、この値を変更しても何のメリットも得られませんでした |
| alpha_value | NTK RoPEスケーリングの位置埋め込みアルファ係数。推奨値(NTKv1):1.5x コンテキストの場合は1.75、2x コンテキストの場合は 2.5。これとcompress_pos_embの両方ではなく、どちらかを使用してください。 |
| rope_freq_base | 0より大きい場合は、alpha_valueの代わりに使用されます。これら2つは、rope_freq_base = 10000 * alpha_value ^ (64 / 63)によって関連付けられます。 |
| compress_pos_emb | 位置埋め込み圧縮係数。(コンテキストの長さ) / (モデルの元のコンテキストの長さ)に設定する必要があります。1/rope_freq_scaleに等しい。 |
| 右列 | 説明 |
| tensorcores | tensorコアのサポートでコンパイルされたllama-cpp-pythonを使用します。これにより、RTX カードのパフォーマンスが向上します。NVIDIAのみ |
| no_offload_kqv | K、Q、VをGPUにオフロードしません。これによりVRAMは節約されますが、パフォーマンスは低下します |
| no_mul_mat_q | Mulmatカーネルを無効にします。通常、このカーネルにより生成速度が大幅に向上します。一部のシステムで機能しない場合に備えて、これを無効にするこのオプションが含まれています |
| no-mmap | モデルを一度にメモリにロードします。ロード時間が長くなり、後で I/O 操作ができなくなる可能性があります。 |
| mlock | スワップや圧縮ではなく、モデルをRAMに保持するようにシステムに強制します(これが何を意味するのかわかりません。一度も使用したことがありません) |
| numa | 特定のマルチCPUシステムのパフォーマンスが向上する可能性があります |
| cpu | GPUアクセラレーションなしでコンパイルされたllama.cppのバージョンを強制的に使用します。通常は無視できます。CPUのみを使用する場合にのみこれを設定し、それ以外の場合はllama.cppが機能しません |
| tensor_split | マルチGPUのみ。GPUごとに割り当てるメモリの量を設定します |
llamacpp_HF
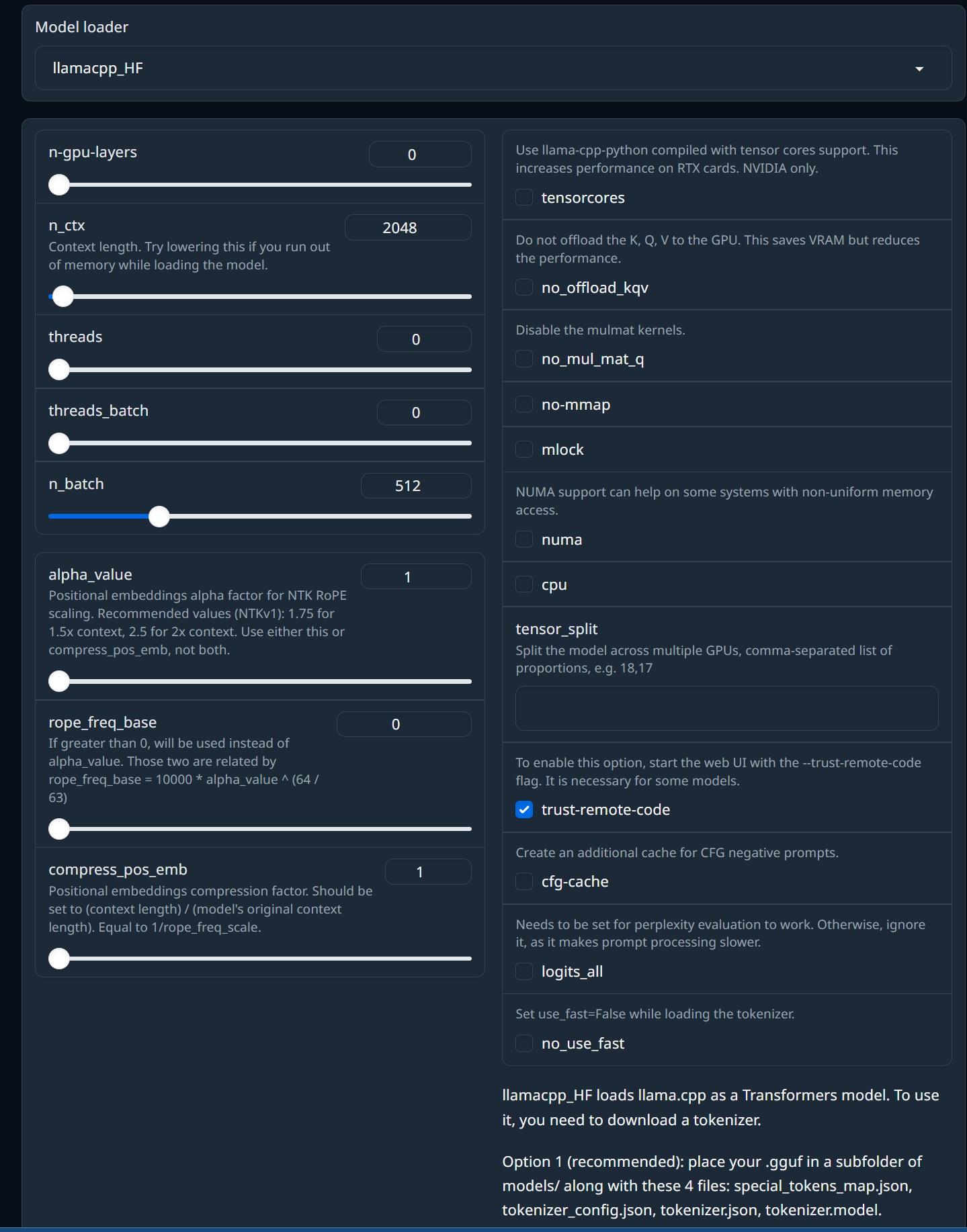
基本的にはllama.cpp と同じですが、transformersサンプラーを使用し、内部のllama.cppトークナイザーの代わりにtransformersトークナイザーを使用します。
使用するには、トークナイザーをダウンロードする必要があります。次の2 つのオプションがあります。
オプション1. Download model or LoRAから"oobabooga/llama-tokenizer"へダウンロードします。これはデフォルトのLlamaトークナイザーです。
オプション2. .ggufを、次の3つのファイルとともに models/のサブフォルダーに配置します:tokenizer.model、tokenizer_config.json、およびspecial_tokens_map.json。これはオプション1よりも優先されます。
追加のパラメータがあります。
| 右列 | 説明 |
| logits_all | "Training" > "Perplexity evaluation"タブを使用してllama.cppモデルの複雑性を評価する場合にチェックする必要があります。それ以外の場合は、プロンプトの処理が遅くなるため、チェックを外したままにしておきます |
ExLlamav2_HF
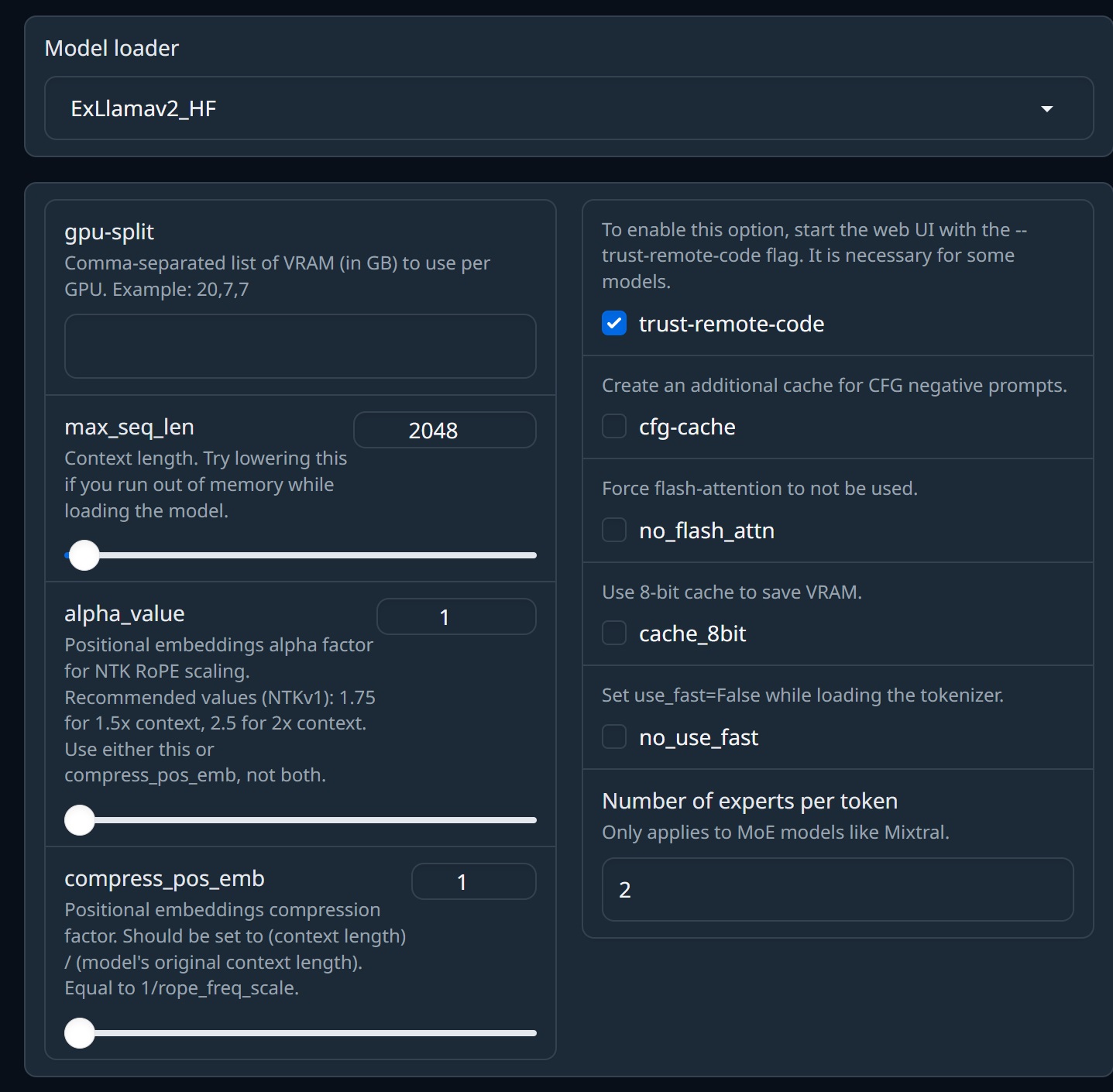
GPTQおよびEXL2モデルをロードするのに使う。
| 左列 | 説明 |
| gpu-split | 複数のGPUがある場合、GPUごとに割り当てるメモリの量をこのフィールドに設定する必要があります。最初のGPUにはキャッシュが割り当てられるため、必ず低い値を設定してください |
| max_seq_len | モデルの最大シーケンス長。ExLlama ではキャッシュが事前に割り当てられるため、この値が大きいほどVRAMが大きくなります。メタデータに基づいてモデルの最大シーケンス長に自動的に設定されますが、モデルをGPUに適合させるには、この値を下げる必要がある場合があります。モデルをロードした後、"Parameters" > "Generation"の下にある"Truncate the prompt up to this length"パラメーターは、選択した"max_seq_len"に自動的に設定されるため、同じものを2回設定する必要はありません。 |
| alpha_value | NTK RoPEスケーリングの位置埋め込みアルファ係数。推奨値(NTKv1):1.5x コンテキストの場合は1.75、2x コンテキストの場合は 2.5。これとcompress_pos_embの両方ではなく、どちらかを使用してください。 |
| compress_pos_emb | 位置埋め込み圧縮係数。(コンテキストの長さ) / (モデルの元のコンテキストの長さ)に設定する必要があります。1/rope_freq_scaleに等しい。 |
| 右列 | 説明 |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| cfg-cache | CFGネガティブプロンプト用に追加のキャッシュを作成します。これは、"Parameters" > "Generation"タブでCFGを使用する場合にのみ設定する必要があります。このパラメータをチェックすると、キャッシュVRAMの使用量が2倍になります。 |
| no_flash_attn | フラッシュアテンションを無効にします。それ以外の場合は、ライブラリがインストールされている限り自動的に使用されます。 |
| cache_8bit | 16ビットのキャッシュではなく8ビット精度のキャッシュを作成します。これによりVRAMは節約されますが、複雑さが増します (どの程度かはわかりません) |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
| Number of experts per token | トークンごとのエキスパートの数。MixtralなどのMoEモデルにのみ適用されます。 |
ExLlamav2
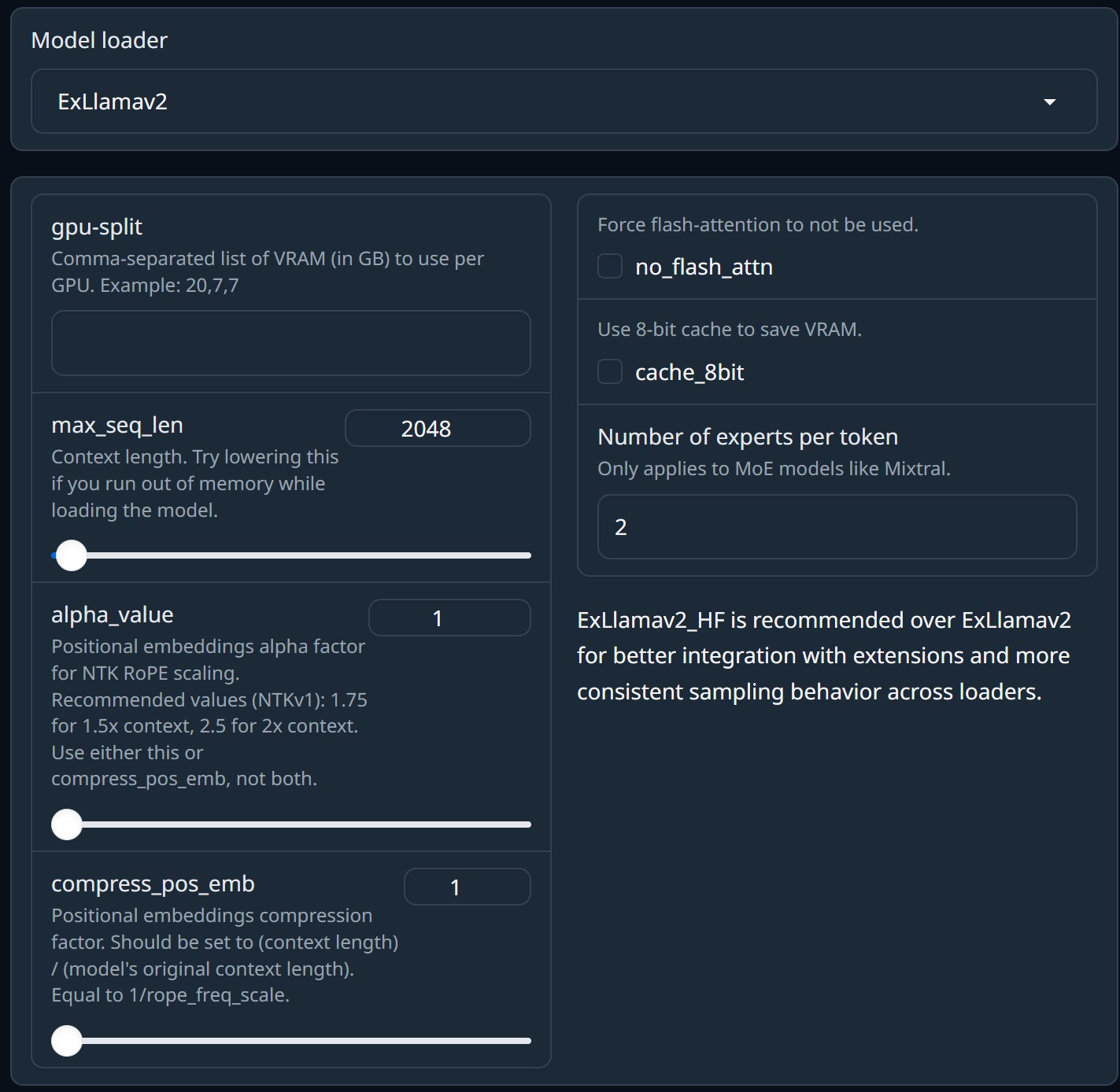
ExLlamav2_HFと同じですが、Transformersライブラリ内のサンプラーの代わりにExLlamav2の内部サンプラーを使用します。
拡張機能との統合を強化し、ローダー間でサンプリング動作の一貫性を高めるために、ExLlamav2よりもExLlamav2_HFを推奨します。
AutoGPTQ
GPTQをロードするのに使う。
| 左列 | 説明 |
| gpu-memory | 使用するVRAM容量を制限できる,VRAM使用量を最大10GiBにしたい場合は、このパラメータを9GiBまたは8GiBに設定する必要がある場合があることに注意してください。私の知る限り、”load_in_8bit”と組み合わせて使用することはできますが、”load-in-4bit”と組み合わせて使用することはできません |
| cpu-memory | 使用するメインメモリ量を制限できる,GPUまたはCPUのどちらにも適合しないものはディスクキャッシュに移動されるため、このオプションを使用するには、”disk”チェックボックスもオンにする必要があります |
| wbits | 適切なメタデータのない古いモデルの場合、モデルの精度をビット単位で手動で設定します。通常は無視できます。 |
| groupsize | 適切なメタデータのない古代モデルの場合、モデル グループ サイズを手動で設定します。通常は無視できます。 |
| 右列 | 説明 |
| triton | Linuxでのみ利用可能です。act-orderとgroupsizeの両方を備えたモデルを同時に使用するために必要です。ExLlamaは、tritonなしでもWindowsにこれらの同じモデルをロードできることに注意してください |
| no_inject_fused_attention | VRAMの使用量を増やしながらパフォーマンスを向上させます |
| no_inject_fused_mlp | 上記のパラメータと似ていますが、Tritonのみに適用されます |
| no_use_cuda_fp16 | 一部のシステムでは、これを設定しないとパフォーマンスが非常に低下する可能性があります。通常は無視できます。 |
| desc_act | 適切なメタデータのない古代モデルの場合、モデルの"act-order"パラメーターを手動で設定します。通常は無視できます |
| cpu | Pytorchを使用してモデルをCPUモードでロードします。モデルは32ビット精度でロードされるため、大量のRAMが使用されます。transformersを使用したCPU推論はllama.cppよりも古く、機能しますが、かなり遅いです。注:このパラメータは、llama.cppローダーでは異なる解釈を持ちます (以下を参照) |
| auto-devices | チェックすると、バックエンドはCPUオフロードでモデルをロードできるように、”gpu-memory”の適切な値を推測しようとします。代わりに”gpu-memory”を手動で設定することをお勧めします。このパラメーターはGPTQモデルをロードする場合にも必要です。その場合、モデルをロードする前にチェックする必要があります |
| disk | GPUとCPUの組み合わせに適合しないレイヤーのディスクオフロードを有効にします |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| disable_exllama | ExLlamaカーネルを無効にします。 |
| disable_exllamav2 | ExLlamav2カーネルを無効にします。 |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
AutoAWQ
AWQモデルをロードするのに使う。
| 左列 | 説明 |
| gpu-memory | 使用するVRAM容量を制限できる,VRAM使用量を最大10GiBにしたい場合は、このパラメータを9GiBまたは8GiBに設定する必要がある場合があることに注意してください。私の知る限り、”load_in_8bit”と組み合わせて使用することはできますが、”load-in-4bit”と組み合わせて使用することはできません |
| cpu-memory | 使用するメインメモリ量を制限できる,GPUまたはCPUのどちらにも適合しないものはディスクキャッシュに移動されるため、このオプションを使用するには、”disk”チェックボックスもオンにする必要があります |
| max_seq_len | コンテキストの長さ。モデルのロード中にメモリが不足した場合は、この値を下げてみてください。 |
| 右列 | 説明 |
| no_inject_fused_attention | VRAMの使用量を増やしながらパフォーマンスを向上させます |
| auto-devices | チェックすると、バックエンドはCPUオフロードでモデルをロードできるように、”gpu-memory”の適切な値を推測しようとします。代わりに”gpu-memory”を手動で設定することをお勧めします。このパラメーターはGPTQモデルをロードする場合にも必要です。その場合、モデルをロードする前にチェックする必要があります |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
GPTQ-for-LLaMa
GPTQモデルをロードするのに使う。
古いGPUとの互換性のためのレガシーローダー。GPTQモデルがサポートされている場合は、ExLlamav2_HFまたはAutoGPTQが優先されます。
| 左列 | 説明 |
| wbits | 適切なメタデータのない古いモデルの場合、モデルの精度をビット単位で手動で設定します。通常は無視できます。 |
| groupsize | 適切なメタデータのない古代モデルの場合、モデル グループ サイズを手動で設定します。通常は無視できます。 |
| model_type | |
| pre_layer | CPUオフロードに使用されます。数値が大きいほど、より多くのレイヤーがGPUに送信されます。GPTQ-for-LLaMa CPUオフロードは、最後に確認したときのAutoGPTQで実装されたものよりも高速でした |
| 右列 | 説明 |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
ctransformers
GGUF/GGMLモデルをロードするのに使う。
llama.cppに似ていますが、Falcon、StarCoder、StarChat、GPT-Jなど、llama.cppで元々サポートされていない特定のGGUF/GGML モデルでも機能します。
| 左列 | 説明 |
| n-gpu-layers | GPUに割り当てるレイヤーの数。0に設定すると、CPUのみが使用されます。すべてのレイヤーをオフロードしたい場合は、これを最大値に設定するだけです。※RTX3060/12GBで30程度? |
| n_ctx | モデルのコンテキストの長さ。llama.cppではキャッシュが事前に割り当てられるため、この値が大きいほどVRAMが大きくなります。GGUFファイル内のメタデータに基づいて、モデルの最大シーケンス長に自動的に設定されますが、モデルをGPUに適合させるには、この値を下げる必要がある場合があります。モデルをロードした後、 "Parameters" > "Generation"の下にある"Truncate the prompt up to this length"パラメーターは、選択した"n_ctx"に自動的に設定されるため、同じものを 2 回設定する必要はありません。 |
| threads | スレッドの数。推奨値:物理コアの数 |
| threads_batch | バッチ処理のスレッド数。推奨値:コアの合計数(物理 + 仮想) |
| n_batch | プロンプト処理のバッチ サイズ。値を大きくすると生成が速くなると考えられていますが、この値を変更しても何のメリットも得られませんでした |
| model_type | |
| 右列 | 説明 |
| no-mmap | モデルを一度にメモリにロードします。ロード時間が長くなり、後で I/O 操作ができなくなる可能性があります。 |
| mlock | スワップや圧縮ではなく、モデルをRAMに保持するようにシステムに強制します(これが何を意味するのかわかりません。一度も使用したことがありません) |
QuIP#
QuIP#はGTPQやAWQより新しい量子化の手法。
※現時点では、QuIP#を手動でインストールする必要があります。
| 右列 | 説明 |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| no_flash_attn | フラッシュアテンションを無効にします。それ以外の場合は、ライブラリがインストールされている限り自動的に使用されます |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
HQQ
HQQはGTPQやAWQより新しい量子化の手法の一つ。
| 左列 | 説明 |
| hqq_backend | バックエンドを選択できる,PYTORCH_COMPILEは最速ですが問題が発生する可能性があります,Pytorchはデフォルトです,ATENは実験的です |
| 右列 | 説明 |
| trust-remote-code | 一部のモデルでは、カスタムPythonコードを使用してモデルまたはトークナイザーを読み込みます。このようなモデルの場合、このオプションを設定する必要があります。リモートコンテンツはダウンロードされません。モデルとともにダウンロードされる.py ファイルを実行するだけです。これらのファイルには悪意のあるコードが含まれている可能性があります。私はそれが起こるのを見たことがありませんが、原理的には可能です |
| no_use_fast | トークナイザーの”fast”バージョンを使用しません。通常は無視できます。モデルのトークナイザーをロードできない場合にのみ、これをチェックしてください |
LoRA
ダウンロード済みLoRAをドロップダウンメニューから選択、ロードします。
Download model or LoRA
Download model or LoRAの欄にHugging Faceで配布されているモデル/LoRAのブランチ名をコピペしてDownloadを押せばダウンロードが開始されます。
GGUFモデルの場合、量子化の精度などごとに複数のモデルが配布されている事があります。Get file listからファイルリストを取得してダウンロードしたい.ggufのファイル名をFile name (for GGUF models)欄にコピペしてDownloadから落とせます。
GGUFモデルの場合、量子化の精度などごとに複数のモデルが配布されている事があります。Get file listからファイルリストを取得してダウンロードしたい.ggufのファイル名をFile name (for GGUF models)欄にコピペしてDownloadから落とせます。
llamacpp_HF creator
GGUFモデルをllamacpp_HFでモデルをロードするのに必要なトークナイザーなどをダウンロードします。
Choose your GGUFからGGUFモデルを選んでEnter the URL for the original (unquantized) modelに量子化前の(元の)モデルのhuggingfaceアドレスを入力、Submitをクリックします。
modelsフォルダに”モデル名-q4_K_M(量子化の精度)-HF”という末尾にHFの付いたサブフォルダが作成されてGGUFファイルとダウンロードされたトークナイザーなどが移動します。
Choose your GGUFからGGUFモデルを選んでEnter the URL for the original (unquantized) modelに量子化前の(元の)モデルのhuggingfaceアドレスを入力、Submitをクリックします。
modelsフォルダに”モデル名-q4_K_M(量子化の精度)-HF”という末尾にHFの付いたサブフォルダが作成されてGGUFファイルとダウンロードされたトークナイザーなどが移動します。
Customize instruction template
これにより、「モデル ローダー」メニューで現在選択されているモデルにカスタマイズされたテンプレートを設定できます。モデルがロードされるたびに、このテンプレートはモデルのメタデータで指定されたテンプレートの代わりに使用されますが、これは間違っている場合があります。
Training
LoRAの作成(学習)と評価を行えます。
Train LoRA
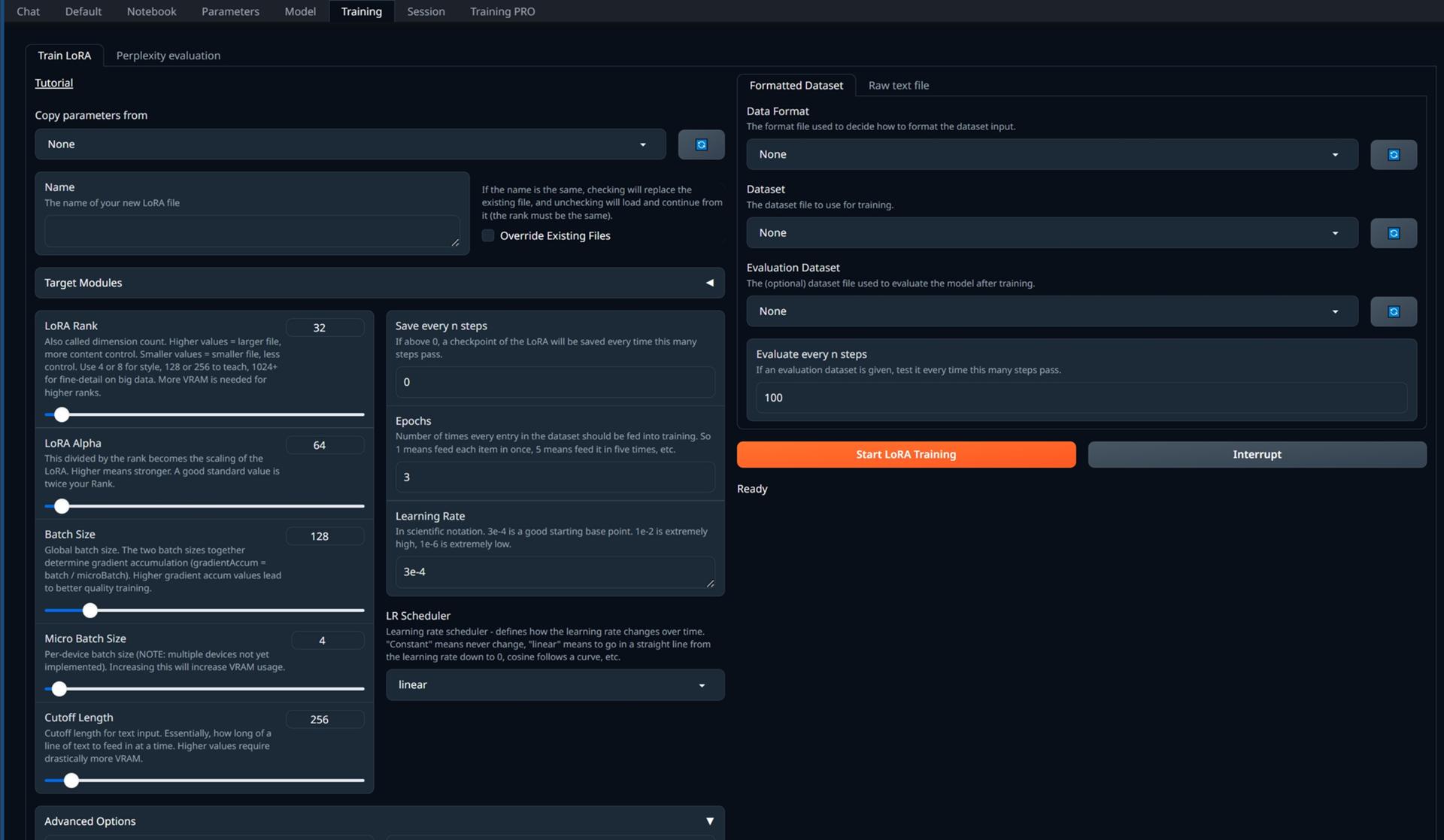
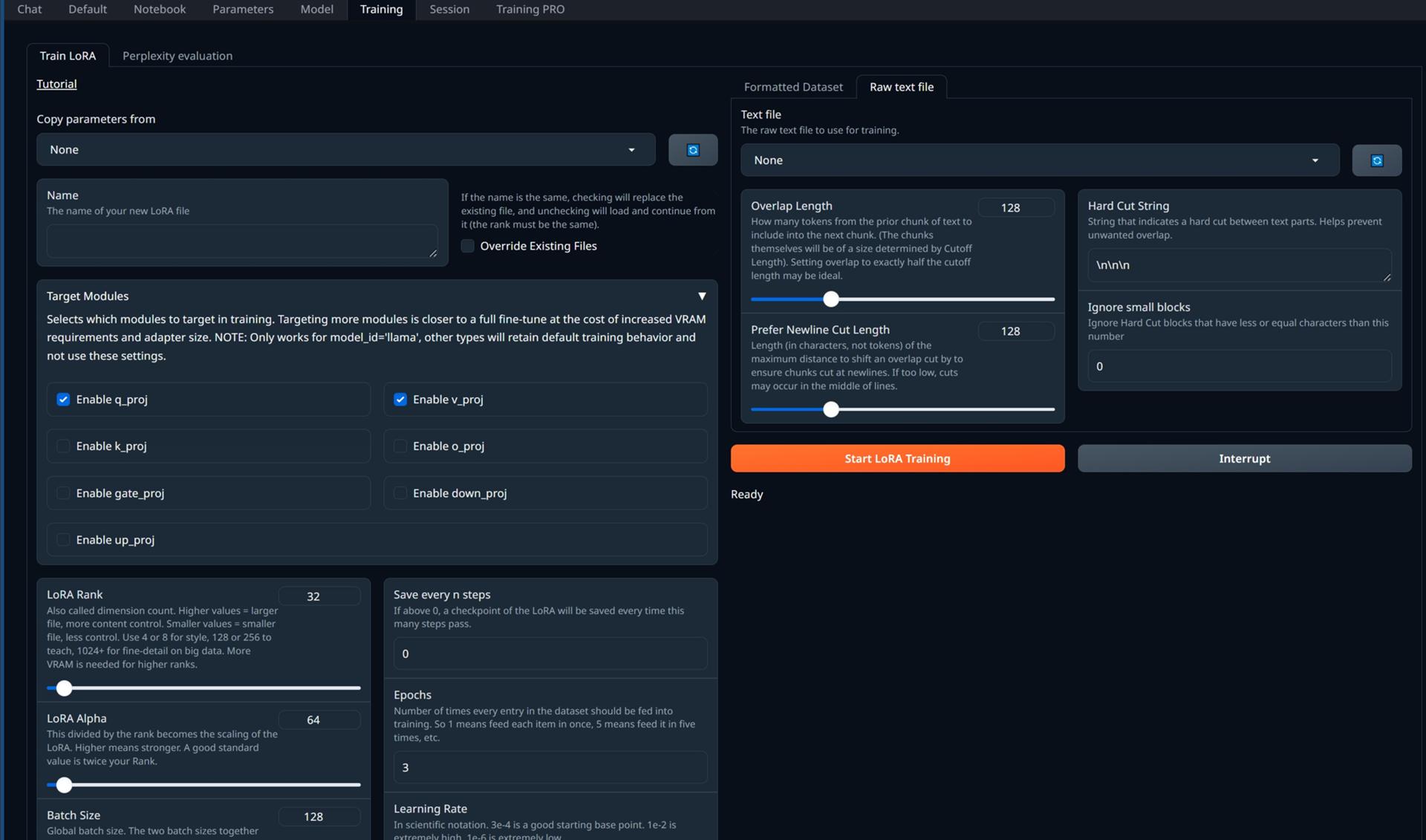
githubのWikiにTutorialページがあります。
| Copy parameters from(パラメータのコピー元) | 設定ファイルからパラメーターのコピー |
| Name(名前) | (作成する)LoRAの名前 |
| Override Existing Files(既存のファイルを上書きする) | 名前が同じ場合、チェックを入れると既存のファイルが置き換えられ、チェックを外すとそのファイルが読み込まれて続行されます (ランクは同じである必要があります)。 |
| Target Modules(対象モジュール) | トレーニングの対象となるモジュールを選択します。より多くのモジュールをターゲットにすると、VRAM要件とアダプターサイズが増加しますが、完全なfine-tuneに近づきます。※model_id='llama' でのみ機能します。他のタイプはデフォルトのトレーニング動作を保持し、これらの設定は使用しません。 |
| LoRA Rank | 次元数とも呼ばれます。値が大きいほどファイルが大きくなり、コンテンツの制御が強化されます。値が小さいほどファイルが小さくなり、制御が少なくなります。スタイルには4または8、教育には128または256、ビッグ データの詳細には1024+を使用します。ランクが高くなるほど、より多くのVRAM が必要になります。 |
| LoRA Alpha | これをRankで割ったものがLoRAのスケーリングになります。 高いほど強いことを意味します。 適切な標準値はランクの2倍です。 |
| Batch Size | グローバルバッチサイズ。2つのバッチサイズを合わせて、勾配の累積(gradientAccum = バッチ / microBatch)が決定されます。 勾配の累積値が高いほど、トレーニングの質が高くなります。 |
| Micro Batch Size | デバイスごとのバッチサイズ (注:複数のデバイスはまだ実装されていません)。これを増やすと、VRAMの使用量が増加します。 |
| Cutoff Length | テキスト入力のカットオフ長。 本質的には、一度にフィードするテキスト行の長さです。 値を大きくすると、大幅に多くのVRAMが必要になります。 |
| Save every n steps | 0より大きい場合、この数のステップが経過するたびにLoRAのチェックポイントが保存されます。 |
| Epochs | エポック数,データセット内の各エントリをトレーニングにフィードする必要がある回数。 つまり、1は各アイテムを1回でフィードすることを意味し、5は5回に分けてフィードすることを意味します。 |
| Learning Rate | 学習率です。1e-2は非常に高く、1e-6は非常に低いです。 |
| LR Scheduler | 学習率スケジューラー ,学習率が時間の経過とともにどのように変化するかを定義します。 "Constant"は決して変化しないことを意味し、"linear"は学習率が0まで直線的に進むことを意味し、"cosine"は曲線に従うなどです。 |
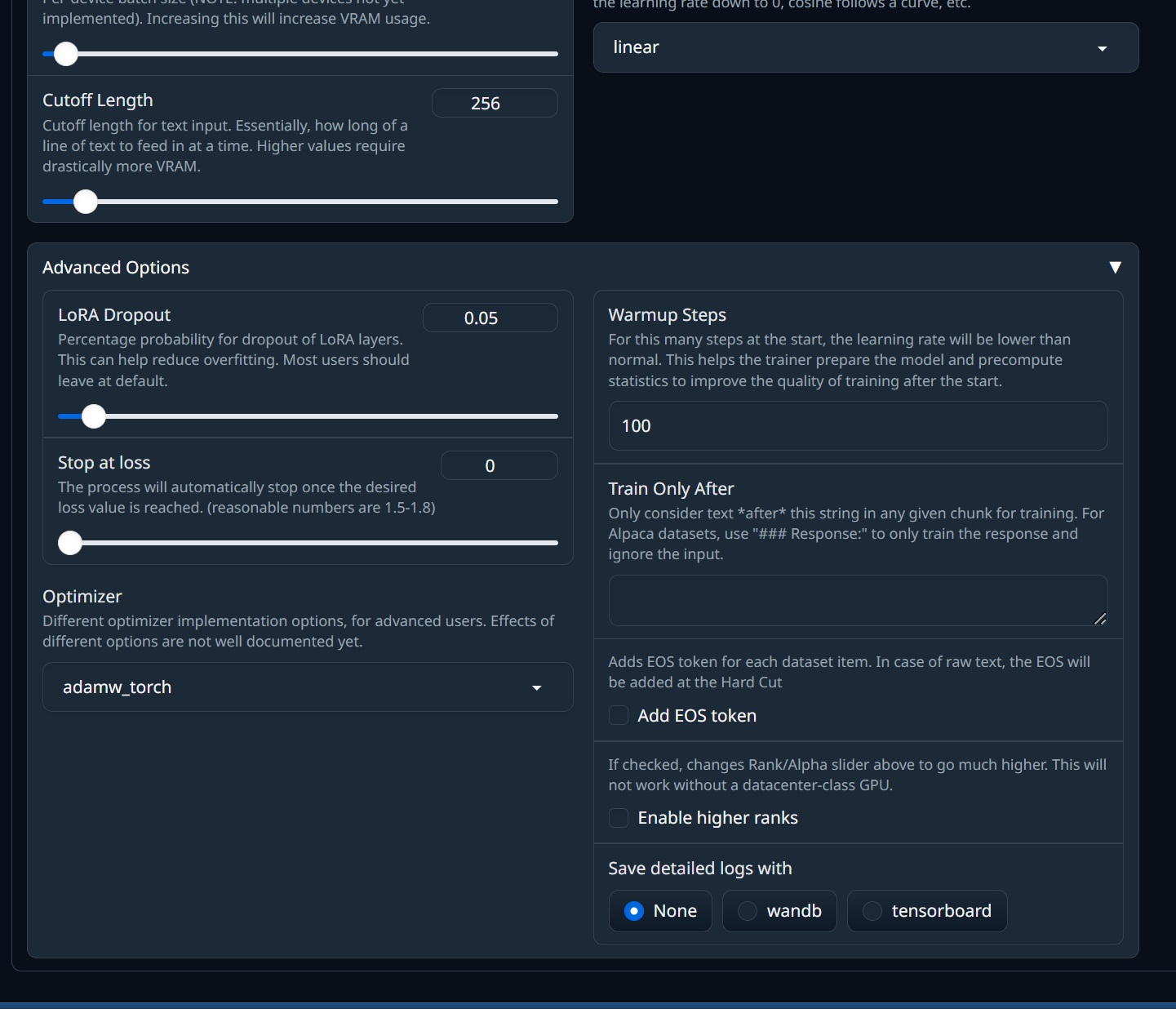
Advanced Options
- Formatted Dataset
| Data Format | データセットのフォーマット方法 |
| Dataset | トレーニングに使用するデータセットファイル |
| Evaluation Dataset | 評価データセット,レーニング後にモデルを評価するために使用される (オプションの)データセットファイル |
| Evaluate every n steps | nステップごとに評価する,評価データセットが指定されている場合は、この数のステップが通過するたびにそれをテストします |
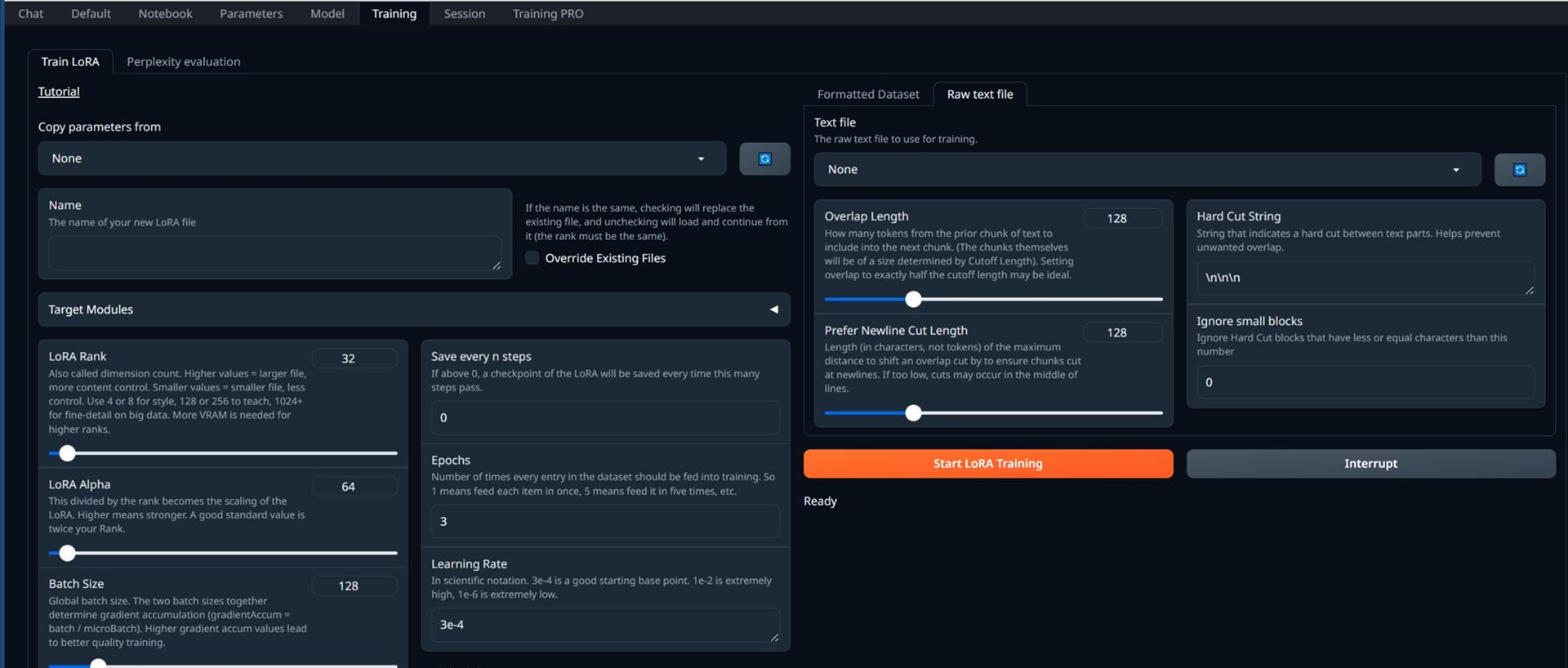
- Raw text file
| Text file | トレーニングに使用する生のテキストファイル |
| Overlap Length | テキストの前のチャンクから次のチャンクに含めるトークンの数。 (チャンク自体のサイズはカットオフ長によって決まります)。 オーバーラップをカットオフ長のちょうど半分に設定するのが理想的です |
| Prefer Newline Cut Length | 改行でチャンクが確実にカットされるように、オーバーラップカットをシフトする最大距離の長さ (トークンではなく文字単位)。 低すぎると、線の途中で切れが発生する可能性があります。 |
| Hard Cut String | テキスト部分間のハードカットを示す文字列。 不要な重なりを防ぐのに役立ちます。 |
| Ignore small blocks | 小さなブロックを無視する,この数以下の文字を含むハード カットブロックを無視します |
- Start LoRA Training
- Interrupt
Perplexity evaluation
Session
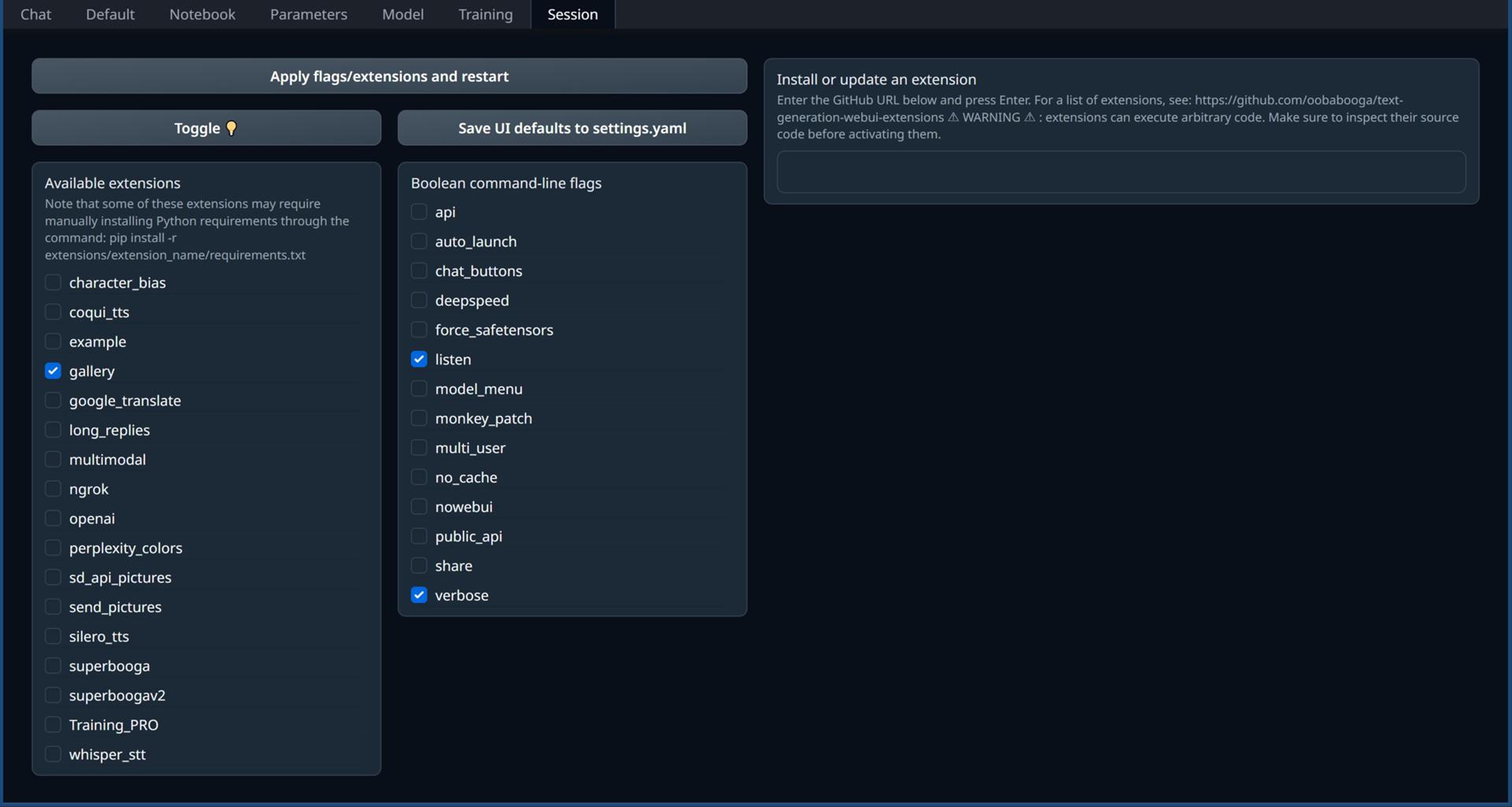
Text generation web UIの設定や拡張機能の有効/無効、インストール、更新などが行なえます。
Toggle 💡からテーマをダーク/ライトに切り替えられます。
"Apply flags/extensions and restart"(フラグ/拡張機能を適用して再起動する)を押す前に"Save UI defaults to settings.yaml"を押して設定を保存しておかないと設定が保存されません。ご注意ください。(WebbUIを再起動すると設定が飛んじゃう)
※"Save UI defaults to settings.yaml"を押すとParametersタブの現在選択しているプリセットなどもデフォルト設定にされます。(変なプリセットを選んでいてもそれがデフォルトになっちゃう)
Boolean command-line flags
| api | API拡張機能を有効にします。 |
| auto-launch | 起動時にデフォルトのブラウザでWeb UI を開きます。 |
| chat-buttons | ホバーメニューの代わりにチャットタブにボタンを表示します。 |
| deepspeed | Transformers 統合による推論にDeepSpeed ZeRO-3の使用を有効にします。 |
| force_safetensors | モデルのロード中にuse_safetensors=Trueを設定します。これにより、任意のコードが防止されます。 |
| listen | ローカルネットワークからWeb UIにアクセスできるようにします。 |
| model-menu | Web UIの最初の起動時にターミナルにモデルメニューを表示します。 |
| monkey-patch | 量子化モデルでLoRAを使用するためのモンキーパッチを適用します。 |
| multi-user | マルチユーザーモード,チャット履歴は保存されず、自動的に読み込まれません。警告:これを一般に共有するのは安全ではない可能性があります。 |
| no-cache | use_cacheをFalseにします。これによりVRAMの使用量がわずかに減少しますが、パフォーマンスが犠牲になります。 |
| nowebui | Gradio Web UIを起動しない。 |
| public-api | Cloudfareを使用してAPIのパブリックURLを作成します。 |
| share | パブリックURLを作成します。これはGoogle ColabなどでWeb UI を実行する場合に便利です。※ローカル環境では有効にすると外部(インターネット)から勝手にアクセスできる状態になるので有効化してはいけません |
| verbose | プロンプトを端末に出力します。 |
Extensions
拡張機能の有効/無効です。
githubのExtensionsページもご覧下さい。
githubのExtensionsページもご覧下さい。
| character_bias | チャットモードでのボットの応答の先頭に非表示の文字列を追加する非常に単純な例です。※この拡張機能を使う事でチャットを行う際に*幸せな気分*などと入力することでバイアスをかけれます。 |
| example | <編集途中> |
| gallery | チャットキャラクターとその写真を含むギャラリーを作成します。 |
| google_translate | Google翻訳を使用して入力と出力を自動的に翻訳します。 |
| long_replies | <編集途中> |
| multimodal | マルチモーダリティのサポート(テキスト+画像)を追加します。詳細な説明については、拡張機能のREADME.mdを参照してください。 |
| ngrok | ngrokリバーストンネルサービス(無料) を使用して、Web UIにリモートでアクセスできます。これは、組み込みの Gradio--share機能の代替です。 |
| openai | OpenAI APIを模倣し、ドロップインの代替として使用できるAPIを作成します。 |
| perplexity_colors | 出力テキスト内の各トークンを、モデルロジットから導出された関連する確率に基づいて色付けします。 |
| sd_api_pictures | チャットモードでボットへ画像をリクエストできます。画像はAUTOMATIC1111 Stable Diffusion APIを使用して生成されます。ここの例を参照してください。 |
| send_pictures | <編集途中> |
| silero_tts | Sileroを使用した音声合成拡張機能。チャットモードで使用すると、応答はオーディオウィジェットに置き換えられます。 |
| superbooga | ChromaDBを使用して、テキスト ファイル、URL、または貼り付けられたテキストを入力として受け取り、任意の大きな疑似コンテキストを作成する拡張機能 |
| superboogav2 | <編集途中> |
| Training_PRO | <編集途中> |
| whisper_stt | マイクを使用してチャットモードで入力を行うことができます。 |