このページは編集途中です
このWikiは主に日本語対応ローカルLLM(大規模言語モデル)関連のメモ的なWikiです。
SillyTavernの使い方などを解説します。
ページの内容が古かったり誤った情報が載っているかもなので気をつけて下さい。
SillyTavernのGitHub
SillyTavern公式Wiki
SillyTavernについて
インストール
Windowsへインストール
アップデート
LinuxへDockerを使ってインストール
アップデート
LinuxへSillyTavern Launcherを使ってインストール
簡単な使い方
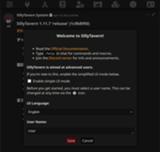
初回起動時に上の画面が出ててきます。
今回はシンプルUIモードを有効にした状態で進めます。※後から無効にして詳細なオプションを表示させることもできます。
”Enable simple UI mode”にチェックを入れたらSaveで設定を保存します。
text-generation-webui(バックエンド)のAPIに接続する
ユーザーの設定
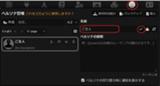
チャットする際のユーザー側の設定(名前やキャラクター設定など)を変更します。
ページ上部の顔のアイコンをクリックします。
ここでは名前を"ご主人"として、名前の入力欄右のチャックボタンをクリックして名前を変更します。
BOTの作成
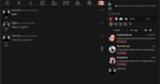
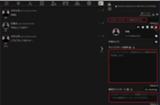
BOTの作成を行います。
ページ上部の一番右のキャラクター管理をクリックします。
新しいキャラクターを作成からキャラクター名、キャラクターの説明、最初のメッセージを入力してキャラクターを作成をクリックします。

{{user}}は現在のユーザー名に、{{char}}はキャラクター名で設定した名前に置き換えられます。
チャットする
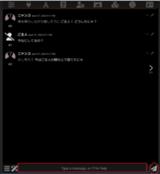
”Type a message, or/? for help”欄にメッセージを入力して右隣のメッセージを送信ボタンをクリックするか[Enter]キーを押して送信します。
※ちなみに[Shift]+[Enter]でメッセージ欄内で改行できます。
詳細など
UI上部左から解説していきます。
ユーザー設定からUIのモードをシンプルから高度に変更しないと一部の設定項目が表示されません。ご注意ください。Common Settings(AI応答の共通設定)
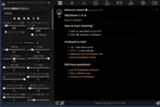
言語モデルを使用してテキストを生成するときのサンプリングプロセスを制御します。
これらの設定は、サポートされているすべてのバックエンドに共通です。
※Text generation web UIのParameters → Generationのように言語モデルのパラメーターの(プリセットへ)設定、変更などが行えます。
コンテキスト設定
応答の長さ(トークン数)
コンテキストのサイズ(トークン数)
サンプラーパラメータ
温度(temperature)
繰り返しペナルティ(反復ペナルティ)
繰り返しペナルティの範囲(反復ペナルティ範囲)
動的温度(Dynamic Temperature)
API接続
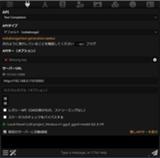
バックエンドへのAPI接続設定です。
APIタイプ
APIキー(オプション)
サーバーURL
その他
高度なフォーマット
コンテキストテンプレート
ストーリー文字列
このWikiは主に日本語対応ローカルLLM(大規模言語モデル)関連のメモ的なWikiです。
SillyTavernの使い方などを解説します。
ページの内容が古かったり誤った情報が載っているかもなので気をつけて下さい。
SillyTavernのGitHub
SillyTavern公式Wiki
SillyTavernについて 
SillyTavernはLLM(大規模言語モデル)のフロントエンド(WebUI)です。SillyTavern単体では言語モデルをロードするバックエンド機能などを持たず、バックエンドとしてoobabooga/text-generation-webuiやkoboldcppなどを必要とします。
SillyTavern自体はバックエンドとするソフトウェアと同じサーバー内で稼働させる必要はなく、ネットワーク上にある別のコンピューターでも動作可能です。
※このWikiでは扱わないがローカルLLMではなく有料のクラウドLLMと接続することもできる
text-generation-webuiやkoboldcppはそれぞれ自前のフロントエンドを持っていますがSillyTavernはロールプレイ/チャット機能に特化しているのが特徴で、ユーザーと(二人以上の)AIエージェント(BOT)とのグループチャット機能なんかもあります。
このページではバックエンドとしてoobabooga/text-generation-webuiを使います。
Text generation web UIページを参考にAPIを有効化しておく必要があります。
SillyTavern自体はバックエンドとするソフトウェアと同じサーバー内で稼働させる必要はなく、ネットワーク上にある別のコンピューターでも動作可能です。
※このWikiでは扱わないがローカルLLMではなく有料のクラウドLLMと接続することもできる
text-generation-webuiやkoboldcppはそれぞれ自前のフロントエンドを持っていますがSillyTavernはロールプレイ/チャット機能に特化しているのが特徴で、ユーザーと(二人以上の)AIエージェント(BOT)とのグループチャット機能なんかもあります。
このページではバックエンドとしてoobabooga/text-generation-webuiを使います。
Text generation web UIページを参考にAPIを有効化しておく必要があります。
インストール
Windowsへインストール
※Windowsが制御するフォルダー (Program Files、System32など) にはインストールしないでください。
※NODEJS 18.16 を実行できないため、Windows 7 へのインストールは不可能です。
※管理者権限でSTART.BATを実行しないでください
※NODEJS 18.16 を実行できないため、Windows 7 へのインストールは不可能です。
※管理者権限でSTART.BATを実行しないでください
- NodeJS(最新のLTS Ver)をインストールします。
- Windows用Gitをインストールします。
- Windowsエクスプローラー(Win+E)を開き、ランチャーをインストールするフォルダーを作成または選択します。
- 上部の”アドレスバー”をクリックして"cmd"と入力してEnter キーを押し、そのフォルダー内でコマンド プロンプトを開きます。
- コマンドプロンプトに次のコマンドを入力してgitからcloneします。
git clone https://github.com/SillyTavern/SillyTavern -b release
- cloneが完了したらコマンドプロンプトを閉じて、SillyTavernフォルダ内のStart.batをダブルクリックして実行します。
アップデート
SillyTavernフォルダ内のUpdateAndStart.batをダブルクリックして実行します。
LinuxへDockerを使ってインストール
GitHubからcloneしてDockerを立ち上げます。
事前に下記のソフトウェアがインストール済みである必要があります。
LAN内の別PCからアクセスできるように./config/にwhitelist.txtという名前のテキストファイルを作成して192.168.0.*と記載して保存します。(ネットワーク環境によっては192.168.1.*だったりします)
SillyTavernを再起動させます。
事前に下記のソフトウェアがインストール済みである必要があります。
- docker
- docker compose
git clone https://github.com/SillyTavern/SillyTavern -b release
cd docker && docker-compose up -d
LAN内の別PCからアクセスできるように./config/にwhitelist.txtという名前のテキストファイルを作成して192.168.0.*と記載して保存します。(ネットワーク環境によっては192.168.1.*だったりします)
SillyTavernを再起動させます。
アップデート
gitからcloneしたディレクトリに移動して
docker-compose pull
LinuxへSillyTavern Launcherを使ってインストール
SillyTavern Launcherのダウンロード
SillyTavern Launcherのインストール
SillyTavern Launcherの起動
git clone https://github.com/SillyTavern/SillyTavern-Launcher && cd SillyTavern-Launcher
SillyTavern Launcherのインストール
chmod +x install.sh && ./install.sh
SillyTavern Launcherの起動
chmod +x launcher.sh && ./launcher.sh
簡単な使い方
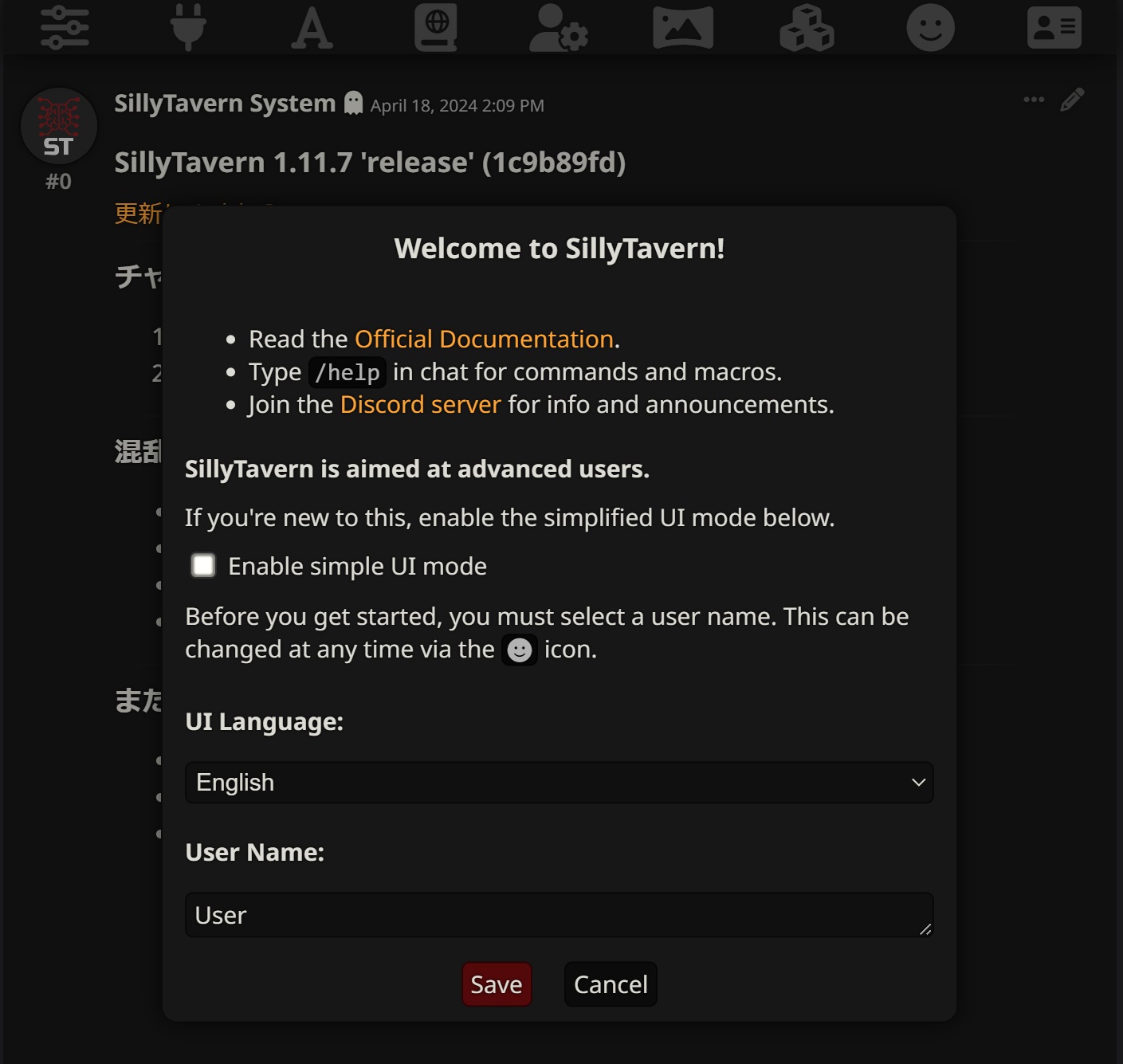
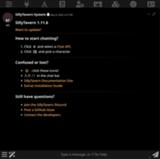
初回起動時に上の画面が出ててきます。
Enable simple UI mode (シンプルUIモードを有効にする)最初はこのオプションを有効にした状態で慣れたほうが良いかもしれません。
今回はシンプルUIモードを有効にした状態で進めます。※後から無効にして詳細なオプションを表示させることもできます。
”Enable simple UI mode”にチェックを入れたらSaveで設定を保存します。
text-generation-webui(バックエンド)のAPIに接続する
oobabooga/text-generation-webuiのAPI機能をText generation web UIのページを参考に有効化したものとして進めます。
※SillyTavern自体は言語モデルをロードする機能を持たないのでtext-generation-webuiなどの他のソフトウェアをバックエンドとしてセットアップする必要があります。
oobabooga/text-generation-webuiのAPI機能を有効化してtext-generation-webuiを起動したら言語モデルをロードします。
今回は例としてTheBloke/Swallow-13B-Instruct-AWQをロードしました。
言語モデルのダウンロード、ロード方法についてはこちらのページをご覧下さい。
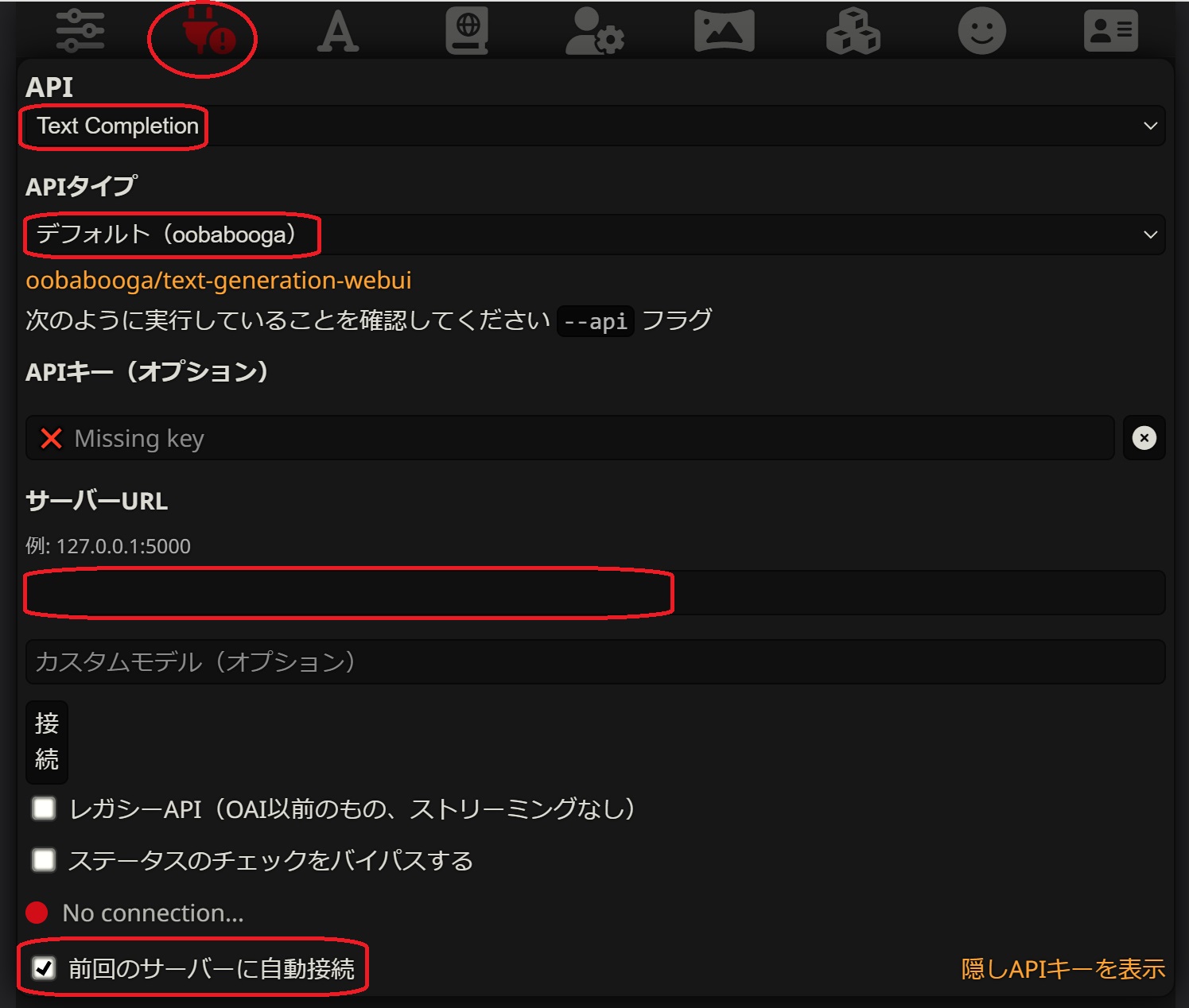
SillyTavernページ上部のコンセントアイコンをクリックしてAPI設定を開きます。
APIをText Completionに、APIタイプをデフォルト (Oobabooga)に変更します。
サーバーURLにhttp://<text-generation-webuiを実行しているPCのアドレス>:5000 (同一PCで実行しているなら、http://127.0.0.1:5000など...)を入力します。
あとは接続をクリックすれば接続されます。
ついでに前回のサーバーに自動接続オプションも有効にしておくと良いかもしれません。
※SillyTavern自体は言語モデルをロードする機能を持たないのでtext-generation-webuiなどの他のソフトウェアをバックエンドとしてセットアップする必要があります。
oobabooga/text-generation-webuiのAPI機能を有効化してtext-generation-webuiを起動したら言語モデルをロードします。
今回は例としてTheBloke/Swallow-13B-Instruct-AWQをロードしました。
言語モデルのダウンロード、ロード方法についてはこちらのページをご覧下さい。
http://<text-generation-webuiを実行しているPCのアドレス>:5000/docsにブラウザでアクセスしてoobabooga/text-generation-webuiのAPI機能が有効なのを確認します。
SillyTavernページ上部のコンセントアイコンをクリックしてAPI設定を開きます。
APIをText Completionに、APIタイプをデフォルト (Oobabooga)に変更します。
サーバーURLにhttp://<text-generation-webuiを実行しているPCのアドレス>:5000 (同一PCで実行しているなら、http://127.0.0.1:5000など...)を入力します。
あとは接続をクリックすれば接続されます。
ついでに前回のサーバーに自動接続オプションも有効にしておくと良いかもしれません。
ユーザーの設定
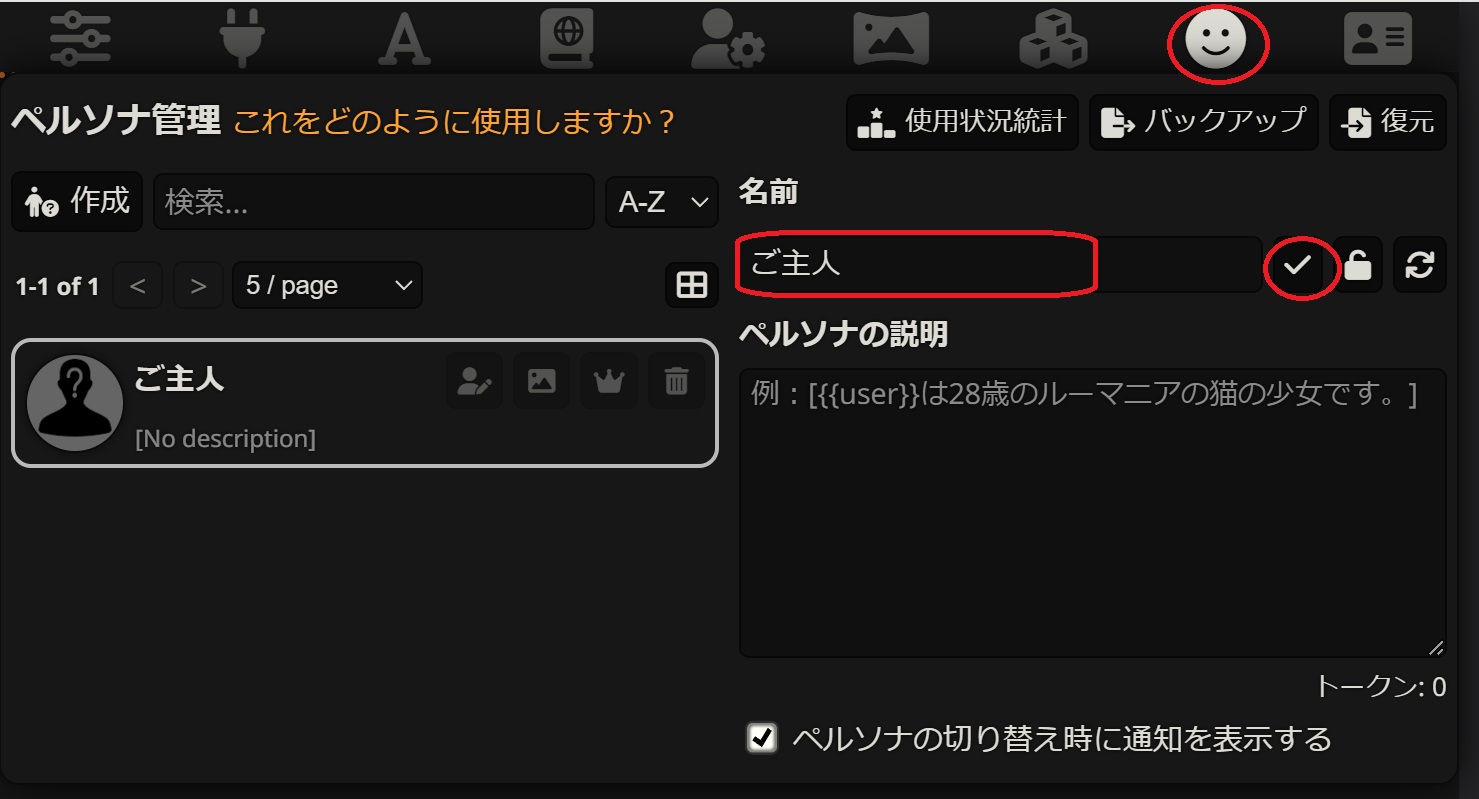
チャットする際のユーザー側の設定(名前やキャラクター設定など)を変更します。
ページ上部の顔のアイコンをクリックします。
ここでは名前を"ご主人"として、名前の入力欄右のチャックボタンをクリックして名前を変更します。
BOTの作成

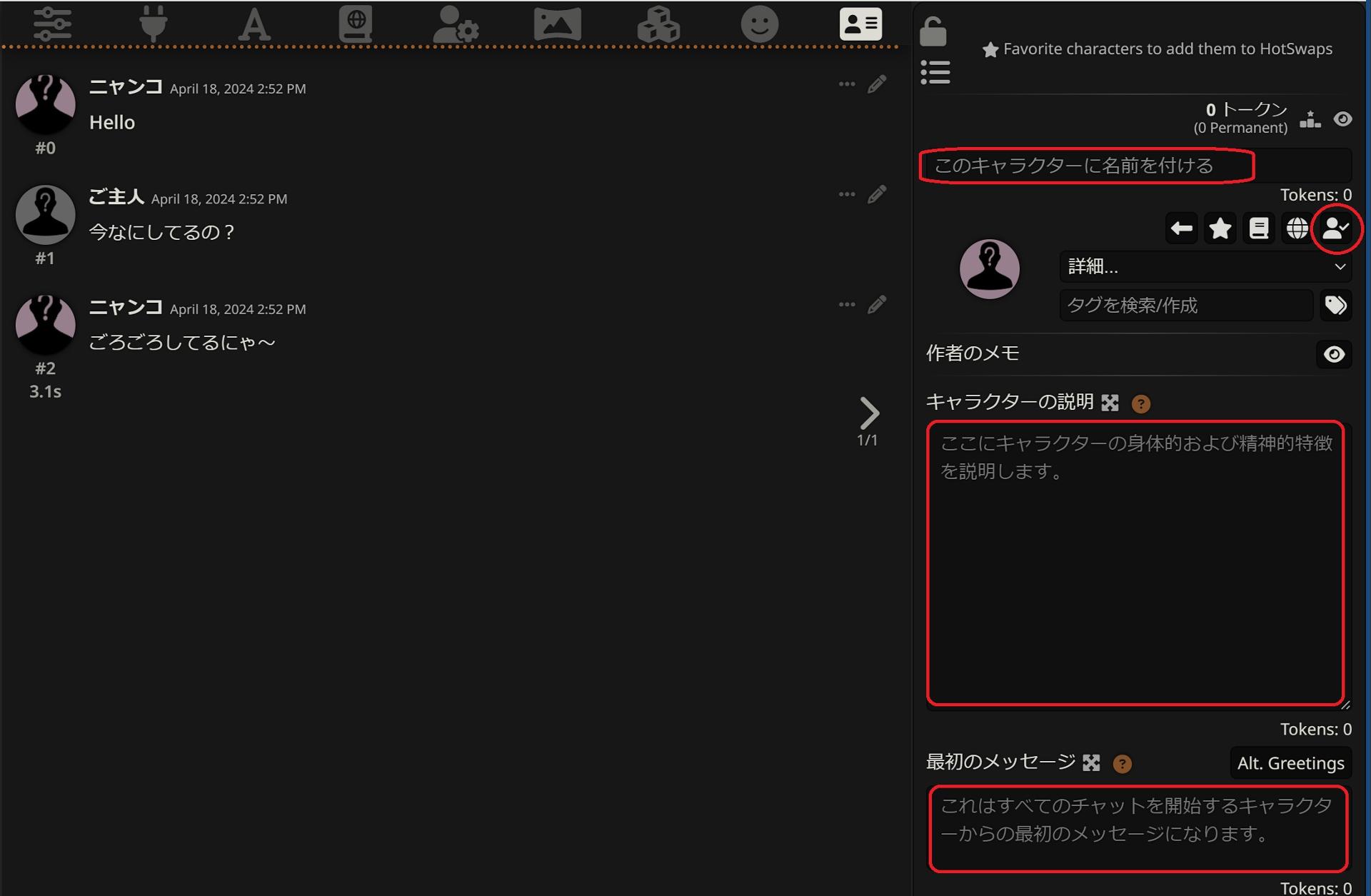
BOTの作成を行います。
ページ上部の一番右のキャラクター管理をクリックします。
新しいキャラクターを作成からキャラクター名、キャラクターの説明、最初のメッセージを入力してキャラクターを作成をクリックします。
例として下記のように入力しました。
{{user}}は現在のユーザー名に、{{char}}はキャラクター名で設定した名前に置き換えられます。
チャットする
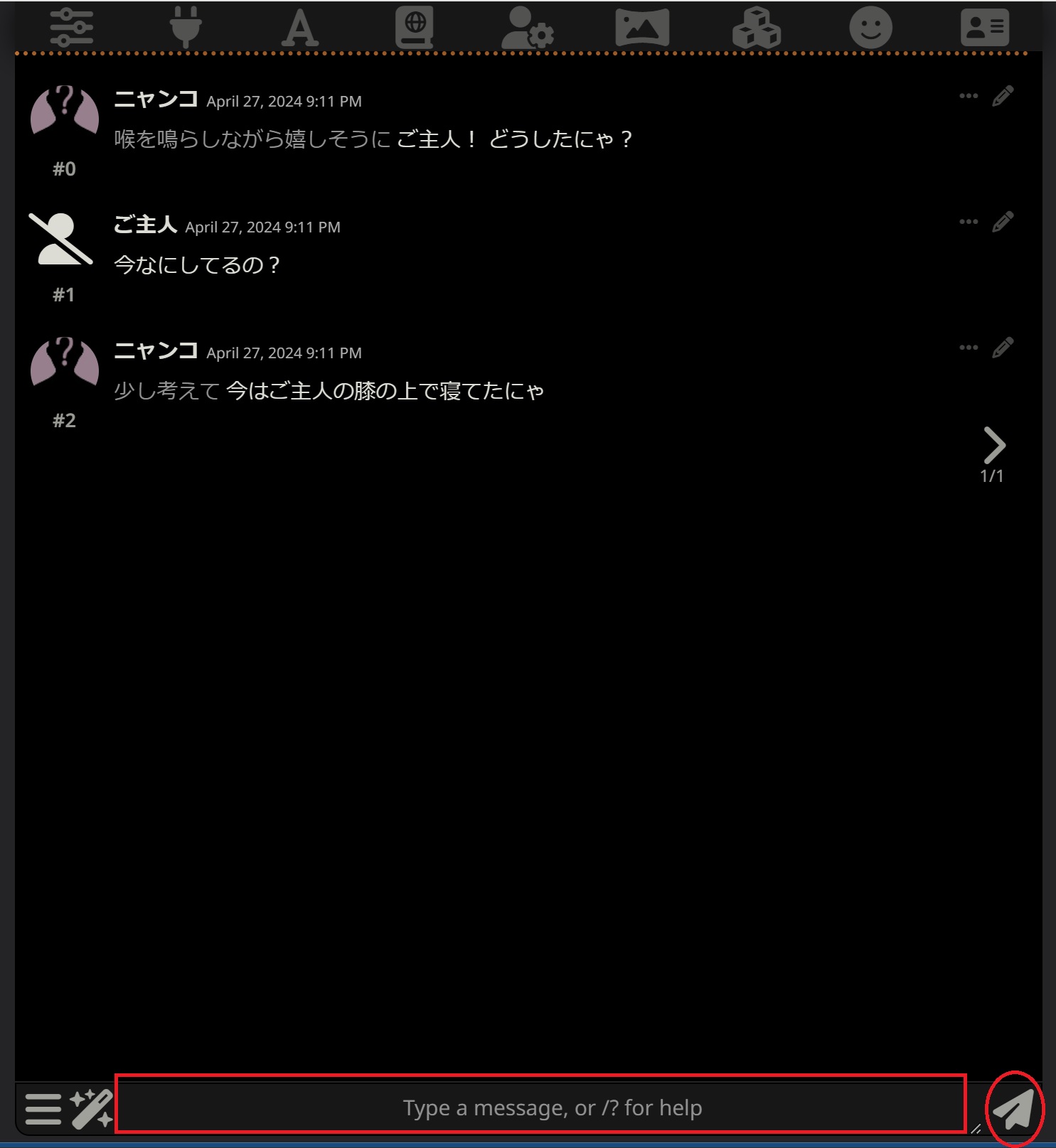
”Type a message, or/? for help”欄にメッセージを入力して右隣のメッセージを送信ボタンをクリックするか[Enter]キーを押して送信します。
※ちなみに[Shift]+[Enter]でメッセージ欄内で改行できます。
詳細など
UI上部左から解説していきます。
ユーザー設定からUIのモードをシンプルから高度に変更しないと一部の設定項目が表示されません。ご注意ください。
Common Settings(AI応答の共通設定)
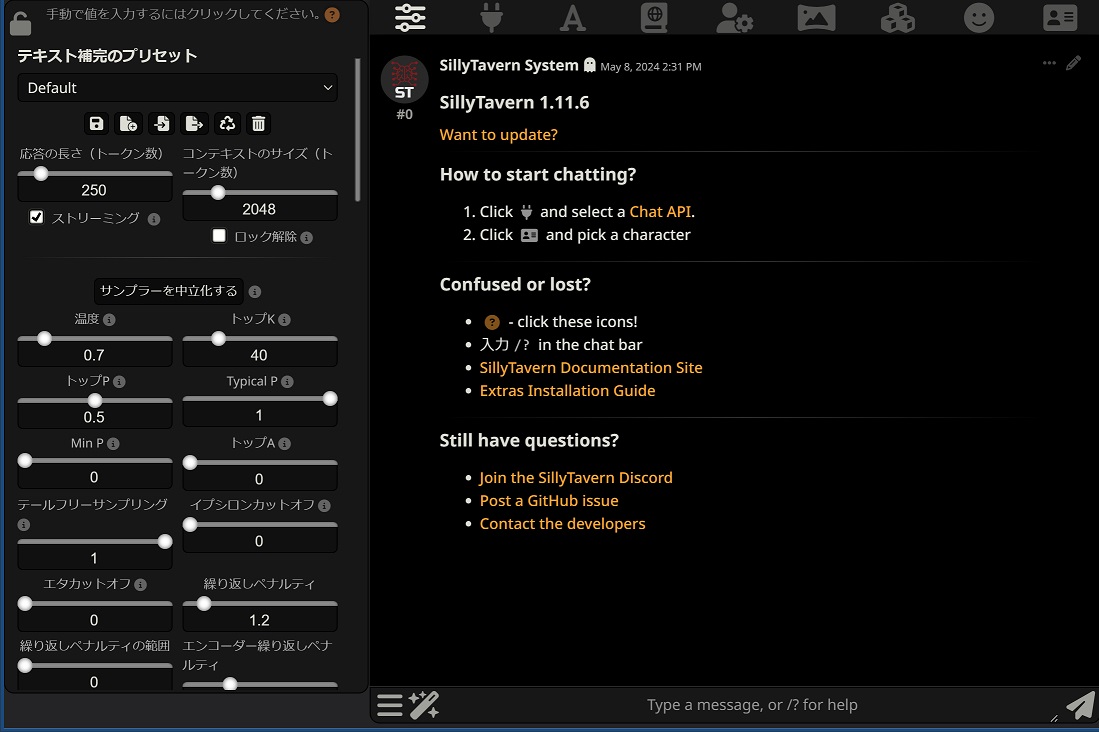
言語モデルを使用してテキストを生成するときのサンプリングプロセスを制御します。
これらの設定は、サポートされているすべてのバックエンドに共通です。
※Text generation web UIのParameters → Generationのように言語モデルのパラメーターの(プリセットへ)設定、変更などが行えます。
コンテキスト設定
応答の長さ(トークン数)
APIが応答(レスポンス)するために生成するトークンの最大数
- 応答(レスポンス)の長さが長いほど、応答の生成にかかる時間が長くなります。
- APIでサポートされている場合は、”ストリーミング”オプションを有効化することで生成中の応答を少しずつ表示することができます。オフの場合、応答が完了した時点で一括表示されます。
コンテキストのサイズ(トークン数)
SillyTavernがプロンプトとしてAPIに送信するトークンの最大数から応答の長さを引いたもの
- コンテキストは文字情報、システム プロンプト、チャット履歴などで構成されます。
- メッセージ間の点線は、チャットのコンテキスト範囲を示します。その線を超えるメッセージはAIに送信されません。
- ロックを解除
サンプラーパラメータ
温度(temperature)
生成されるテキストのランダム性を制御します。
値が大きいほどランダム性が高くなります。
※値を上げると創造的になり、小説の執筆などに向く。逆に下げるとQ&Aなどの回答の質が上がる?
値が大きいほどランダム性が高くなります。
※値を上げると創造的になり、小説の執筆などに向く。逆に下げるとQ&Aなどの回答の質が上がる?
繰り返しペナルティ(反復ペナルティ)
コンテキスト内でのトークンの出現頻度に基づいてトークンにペナルティを課すことで、繰り返しを抑制しようとします。
- 場合によっては、キャラクターが何かに固執している場合、または同じフレーズを繰り返す場合、このパラメータを増やすと役立つことがあります。
繰り返しペナルティの範囲(反復ペナルティ範囲)
最後に生成されたトークンからのトークンの数が反復ペナルティの対象となります。 「the、a、and」などの一般的な単語が最もペナルティを受けるため、設定が高すぎると応答が中断される可能性があります。
※無効にするには、値を 0 に設定します。
※無効にするには、値を 0 に設定します。
動的温度(Dynamic Temperature)
最上位トークンの可能性に基づいて温度(temperature)を動的に調整します。一貫性を犠牲にすることなく、より創造的な出力を生み出すことを目指しています。
最低temperatureから最高temperatureまでのtemperature範囲を受け入れます。
最低temperatureから最高temperatureまでのtemperature範囲を受け入れます。
API接続
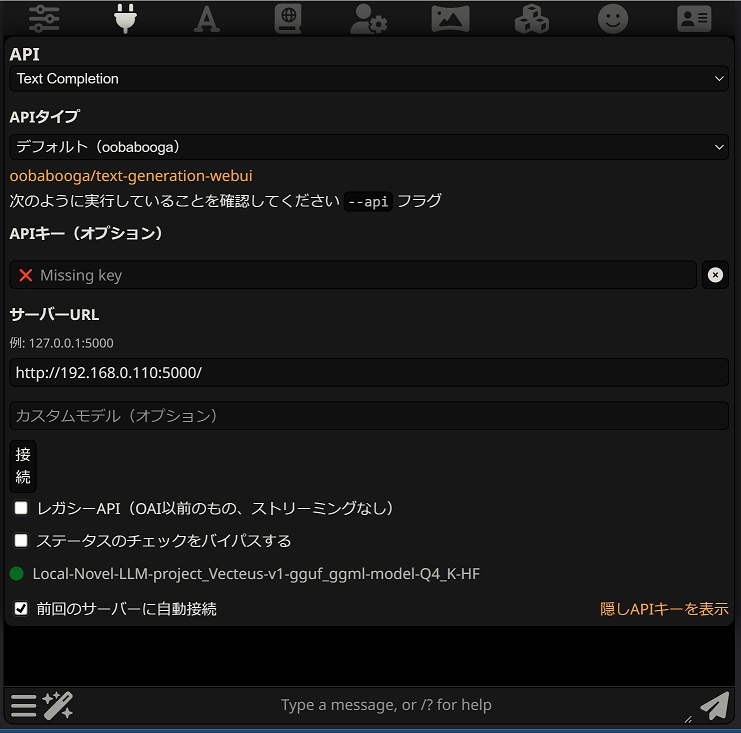
バックエンドへのAPI接続設定です。
APIタイプ
バックエンドとするソフトウェアを選択します。
APIキー(オプション)
クラウドLLMサービスへのAPI接続に必要となります。
サーバーURL
APIのサーバーURLを入力します。
http://<アドレス>:<port>/ローカルPCで実行している例: 127.0.0.1:5000
その他
- 接続 サーバーへ接続します。
- 前回のサーバーに自動接続 前回接続したサーバーに自動接続します。
高度なフォーマット
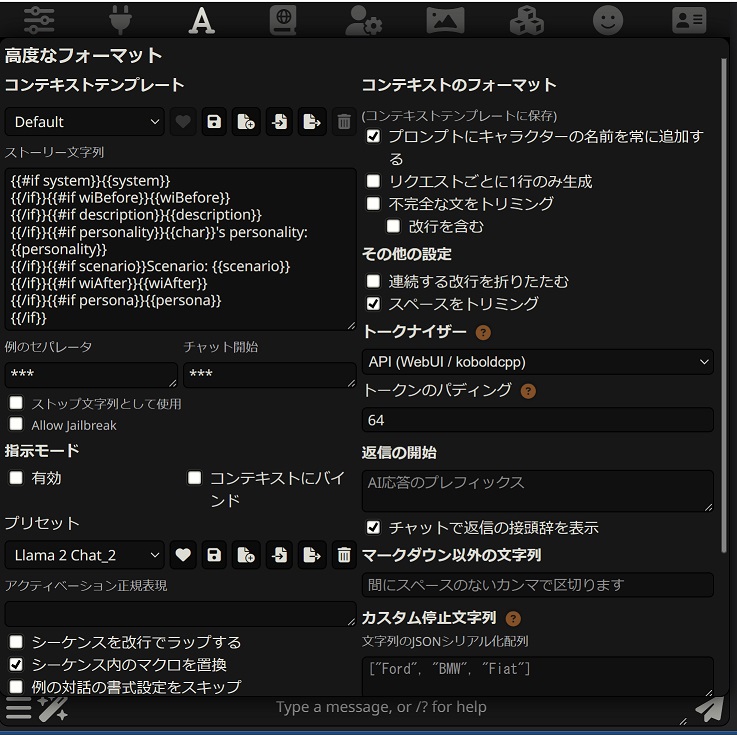
コンテキストテンプレート
通常、AIモデルでは、何らかの特定の方法でキャラクターデータをAIモデルに提供する必要があります。 SillyTavernには、さまざまなモデル用の事前に作成された変換ルールのリストが含まれていますが、それらを自由にカスタマイズできます。
ストーリー文字列
このフィールドは、プリチャット文字データ (内部的にはストーリー文字列として知られています) のテンプレートです。これは、テキスト補完用にキャラクターカードをフォーマットし、モデルに指示する主な方法です。
このテンプレートは、Handlebars構文とカスタムテキストインジェクションまたは書式設定をサポートしています。こちらの言語リファレンスを参照してください: https://handlebarsjs.com/guide/
次のパラメータを Handlebars エバリュエーターに提供します (二重中括弧{{}}で囲みます)。
このテンプレートは、Handlebars構文とカスタムテキストインジェクションまたは書式設定をサポートしています。こちらの言語リファレンスを参照してください: https://handlebarsjs.com/guide/
次のパラメータを Handlebars エバリュエーターに提供します (二重中括弧{{}}で囲みます)。
- description キャラクターの説明
- scenario キャラクターのシナリオ
- personality キャラクターの性格
- system [命令モード] システムプロンプトまたはキャラクターのメイン プロンプト オーバーライド(存在し、ユーザー設定で「文字プロンプトを優先」が有効になっている場合)
- persona 選択したペルソナの説明
- char キャラクターの名前
- user 選択したペルソナ名