このページは編集途中です
このページではローカルLLMでロールプレイ/チャットや小説執筆を行うプロンプトの書き方などを解説します。
ページの内容が古かったり誤った情報が載っているかもなので気をつけて下さい。
モデルによって決められたフォーマットがあったりプロンプトとの相性もありますのでご注意ください。
※このページではTheBloke/Swallow-13B-Instruct-AWQを使用した際のプロンプト例などを解説します。
※このページではLocal-Novel-LLM-project/Vecteus-v1(正確にはGGUF版を使用した際のプロンプト例などを解説します。
そもそもプロンプトチューニングってなんぞ
プロンプトの基本的な事など
キャラクターと(ロールプレイ)チャットする際のプロンプト例
Ali:Chat(話し方や語尾の指定、キャラの設定などをインタビュー形式などで記載する)
PList(キャラクターの性格や衣服などをトークンを節約しつつ記載する)
Markdown形式(**、斜体)で行動や状況、表情などを表現させる
小説を書かせる際のプロンプト例
このページではローカルLLMでロールプレイ/チャットや小説執筆を行うプロンプトの書き方などを解説します。
ページの内容が古かったり誤った情報が載っているかもなので気をつけて下さい。
モデルによって決められたフォーマットがあったりプロンプトとの相性もありますのでご注意ください。
※このページではLocal-Novel-LLM-project/Vecteus-v1(正確にはGGUF版を使用した際のプロンプト例などを解説します。
そもそもプロンプトチューニングってなんぞ 
LLMは入力されたテキスト(プロンプト)の続きを予測して出力する。
この入力するテキストを工夫することで出力を良いものにしよう、というのがプロンプトチューニング(プロンプトエンジニアリングとも)
対して言語モデル自体に追加学習などを行うのをファインチューニングと呼ぶ。
この入力するテキストを工夫することで出力を良いものにしよう、というのがプロンプトチューニング(プロンプトエンジニアリングとも)
対して言語モデル自体に追加学習などを行うのをファインチューニングと呼ぶ。
プロンプトの基本的な事など
huggingfaceのBest practices of LLM promptingによれば、
そのほか、

上記の例では"###"でテキストを構造化していますが、XML形式(厳格である必要はない)で記載するのも良いらしいです。
その他、Markdown形式でプロンプトを記載する方法もあります。
※言語モデルとの相性もあります!
※モデルによってはフォーマットが指定されているものもあります。
あと、コンテキスト内の位置も関係するらしいです。
(最後に記載したプロンプトの方が最初に記載したプロンプトより強いらしい)
このため、チャットする際はCharacterのGreetingは必須ではないにせよ、会話の流れを持っていくのに重要です。(send to default(デフォルトに送信)を行えばわかりますがGreetingテキストが最後に来るので)
※会話例なども最後の方に記載した方が良い感じ?
チャットの場合だとキャラ設定などのContextは保持される(常に言語モデルに渡される)がチャット履歴はContextの上限を超えると古いものから削除されて言語モデルに渡されるので長々とチャットすると最初の方のやり取りを忘れてしまう。
→できるだけプロンプトをシンプルにしてトークン数を節約する方が良い
※推奨値は1.5だが1.5だと強すぎるように感じる(→プロンプトが悪いのかも)
例えばコンテキストに語尾を指定しているのに無視される場合、guide_scaleの値をあげる事である程度矯正できます。
当然ですがコンテキスト内のほかのプロンプトも強くなるのであまり上げすぎると会話例などを含んでいる際、会話例がそのまま帰ってきたりします。
(固定しないと例えば悪い結果が出た時、プロンプトが悪いのかたまたまシードが悪かったのかわからない....)
Text generation web UIの"Parameters" → "Generation" → "Preset"の"Seed (-1 for random)"からシード値を固定できますが、これはPytorchのシードを固定するものでllama.cppなど一部のローダーでは固定できません。ご注意ください。
- シンプルで短いプロンプトから始める
- 指示はプロンプトの最初、または最後にする(〜になりきってチャットしてください、などを最初または最後に)
- 指示と、それが適用されるテキストを明確に区別する
- タスクと望ましい結果 (その形式、長さ、スタイル、言語など) について具体的かつ説明的にする
- 曖昧な説明や指示は避ける
- 「何をしてはいけないか」という指示ではなく、「何をすべきか」という指示を優先する(”☓☓しないでください”など否定語を使わない)
そのほか、
- テキストを構造化する
小説を書かせる際の例:
上記の例では"###"でテキストを構造化していますが、XML形式(厳格である必要はない)で記載するのも良いらしいです。
小説を書かせる際の例 XML形式:
その他、Markdown形式でプロンプトを記載する方法もあります。
※言語モデルとの相性もあります!
※モデルによってはフォーマットが指定されているものもあります。
あと、コンテキスト内の位置も関係するらしいです。
(最後に記載したプロンプトの方が最初に記載したプロンプトより強いらしい)
このため、チャットする際はCharacterのGreetingは必須ではないにせよ、会話の流れを持っていくのに重要です。(send to default(デフォルトに送信)を行えばわかりますがGreetingテキストが最後に来るので)
※会話例なども最後の方に記載した方が良い感じ?
- Contextに記載できるトークン数(文字数ではない)には限りがある(Llama2モデルは4,096トークン)
チャットの場合だとキャラ設定などのContextは保持される(常に言語モデルに渡される)がチャット履歴はContextの上限を超えると古いものから削除されて言語モデルに渡されるので長々とチャットすると最初の方のやり取りを忘れてしまう。
→できるだけプロンプトをシンプルにしてトークン数を節約する方が良い
- guide_scale(CFG)でプロンプトの強度を上げれる
※推奨値は1.5だが1.5だと強すぎるように感じる(→プロンプトが悪いのかも)
例えばコンテキストに語尾を指定しているのに無視される場合、guide_scaleの値をあげる事である程度矯正できます。
当然ですがコンテキスト内のほかのプロンプトも強くなるのであまり上げすぎると会話例などを含んでいる際、会話例がそのまま帰ってきたりします。
- Seedを固定してプロンプトをテストする
(固定しないと例えば悪い結果が出た時、プロンプトが悪いのかたまたまシードが悪かったのかわからない....)
Text generation web UIの"Parameters" → "Generation" → "Preset"の"Seed (-1 for random)"からシード値を固定できますが、これはPytorchのシードを固定するものでllama.cppなど一部のローダーでは固定できません。ご注意ください。
キャラクターと(ロールプレイ)チャットする際のプロンプト例
※チャットする際、言語モデルに渡されるプロンプトに(WebUIなどで設定した)キャラクター名も含まれるので有名なアニメや漫画のキャラクター/実在する有名人など(言語モデルの学習データに含まれているような名前)をキャラクター名にするとそちらに(設定などが)引っ張られる事があるそうです。ご注意ください。
Text generation web UIやSillyTavernではコンテキスト内に記載する、ユーザー名などを置き換える特殊なテキストがあります。
よく使うものとしてユーザー名 {{user}} 、キャラクター名 {{char}} などがあります。
これらをコンテキスト内に記載すると名前欄に設定した名前に置き換えられて言語モデルに渡されます。
Text generation web UIやSillyTavernではコンテキスト内に記載する、ユーザー名などを置き換える特殊なテキストがあります。
よく使うものとしてユーザー名 {{user}} 、キャラクター名 {{char}} などがあります。
これらをコンテキスト内に記載すると名前欄に設定した名前に置き換えられて言語モデルに渡されます。
Ali:Chat(話し方や語尾の指定、キャラの設定などをインタビュー形式などで記載する)
{{user}}: 自己紹介して?
{{char}}: *眠そうにあくびをしながら視線をこちらへ向けて* わかったにゃ。にゃーは{{char}}という名前の猫にゃ。飼い主は{{user}}にゃ。好きなものはご飯とチュール、イタズラにゃ。...もういいにゃ? *日当たりの良い窓辺へ移動して丸くなる*
PList(キャラクターの性格や衣服などをトークンを節約しつつ記載する)
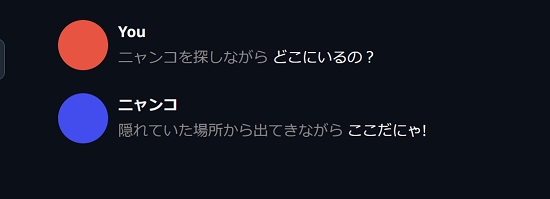
Markdown形式(**、斜体)で行動や状況、表情などを表現させる
Text generation web UIやSillyTavernのチャットタブはユーザーの入力/LLMからの出力ともにMarkdown形式に対応しています。
これを利用してコンテキストに記載するプロンプトの会話例などをMarkdown形式にして状況や表情などを表現させれます。
これを利用してコンテキストに記載するプロンプトの会話例などをMarkdown形式にして状況や表情などを表現させれます。
コンテキストに記載するプロンプトの例